TOC Fundamentals
Main Source:
- Theory of computation — Wikipedia
- Book chapter 0
- Finite state machine — Wikipedia
- Introduction to Theory of Computation — Neso Academy
- Finite State Machine (Prerequisites) — Neso Academy
Introduction
Section titled “Introduction”Theory of Computation (TOC) is the study of abstract models of computation and the fundamental limits of what can be computed. It seeks to understand the nature of computation, the power, and limitations of different computational models, and the relationships between different classes of problems.
This field is further divided into three:
- Automata Theory & Formal Language: Automata theory is the study of abstract models of computation or machines used to solve computational problems. Formal language is concerned about formalizing a natural language by specifying with symbols or character, following a set of rules called the formal grammar. Automata are designed to recognize formal language. In other word, the formal language is used as the input and output for the abstract model of computation. Different types of automata recognize different types of languages.
- Computability Theory: Computability theory focuses on the study of what can be computed and the limits of computation. It deals with the question of which problems can be solved algorithmically and which problems are unsolvable. Problems are analyzed with abstract model of computation along with other formal systems.
- Computational Complexity Theory: Computational complexity theory focuses on understanding the resources required to solve computational problems. It focuses on classifying problems into different complexity classes based on the amount of time, space, or other resources needed to solve them.
Foundational Concepts
Section titled “Foundational Concepts”TOC uses much math.
Notation
Section titled “Notation”TOC uses mathematical logics as the tool to formalize and analyze computational concepts. Therefore, there are various mathematical notation used here. These notations will be covered later.


Source: Book notation part
In mathematical logic, set is a collection of objects. The objects within a set can be anything from numbers, letters, other sets, or even more abstract mathematical objects.
Sets are typically denoted using curly braces . For example, the set of natural numbers less than 5 can be written as , where each number is an element of the set. If an object is an element of a set , it is represented as , and if is not an element of , it is represented as .
Sets can be finite or infinite, depending on the number of elements they contain. For example, the set of all even numbers is an infinite set, while the set of colors in a rainbow is a finite set.
Set operations and terminologies:
-
Empty set: A set is empty, denoted as if it contains no elements.
-
Union: The union of two sets and , denoted by , is the set that contains all the elements that are in either set A or set B, or in both. For example, if # and , then .
-
Intersection: The intersection of two sets and , denoted by , is the set that contains all the elements that are common to both and . For example, if and , then .
-
Set difference: denotes the difference between set and . It is a set that contains everything in , but not in . For example, if and , then .
-
Complement: Denoted by , is a set that contains everything that is not in .
-
Properties: Set has some properties as follows.
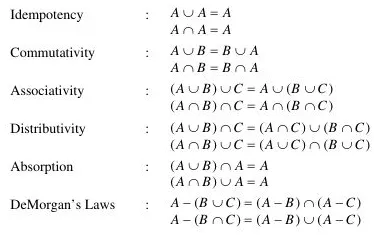
Source: Book page 2-3 -
Subset: A set is said to be a subset of a set if every element of is also an element of . If and , then is a subset of (). It is possible for a set to be a subset of another set without being equal to it. If is a subset of and there exists at least one element in that is not in , then is called a proper subset of , denoted as .
-
Superset: Conversely, a set is said to be a superset of a set if every element of is also an element of . In other words, if every element in satisfies the condition , then is a superset of , denoted as . Similar to subsets, if is a superset of and there exists at least one element in that is not in , then is a proper superset of , denoted as .
-
Disjoint sets: Disjoint sets are sets that have no elements in common. In other words, two sets and are disjoint if their intersection is the empty set . For example, if and , then and are disjoint sets because their intersection is .
-
Cardinality: The number of element in some set. The cardinality of a set is denoted as .
-
Powerset: The powerset of a set , denoted as , is the set that contains all possible subsets of , including the empty set and the set itself. For example, if , then .
-
Cartesian Product: The Cartesian product of two sets and , denoted as , is the set of all possible ordered pairs where the first element comes from and the second element comes from . In other words, it combines every element of with every element of . For example, if and , then .
Relations
Section titled “Relations”Relation is a set of ordered pairs that relates elements from one set, called the domain, to elements of another set, called the range or codomain. More specifically, a relation on sets and is a set of ordered pairs , where:
- and need not be different
- The set of all first elements in the “domain” of the relation, and
- The set of all second elements is the “range” of the relation
Two sets and . A relation from to could be . This relation relates each element from set with a corresponding element from set .
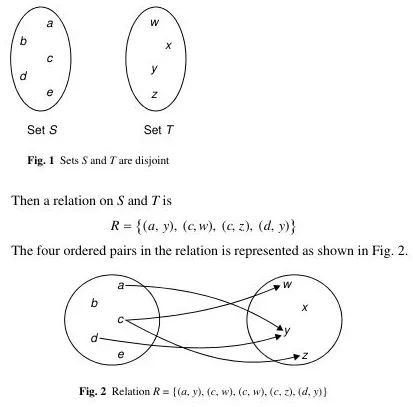
Source: Book page 8-9
- Equivalence Relations: An equivalence relation is a relation that satisfies three properties:
- Reflexivity: Every element is related to itself. For all elements in the set, is in the relation.
- Symmetry: If one element is related to another, then the other is related to the first. For all elements and in the set, if is in the relation, then is also in the relation.
- Transitivity: If one element is related to a second, and the second is related to a third, then the first is related to the third. For all elements , , and in the set, if is in the relation and is in the relation, then is also in the relation.
- Partial Ordering Relation: A relation that satisfies three properties: reflexivity, antisymmetry, and transitivity. A set with a relation being partial order is called partially ordered set.
- Antisymmetry: The opposite of symmetry, for all elements and in the set, if is in the relation, then must not be in the relation, unless .
- Partition: A partition of a set is a collection of non-empty, disjoint subsets (called blocks) that cover the entire set. Each element of the set belongs to exactly one block of the partition. A set can be partitioned into .
Functions
Section titled “Functions”A function is a special type of relation that assigns a unique element from the range to each element in the domain. In other words, it relates each element in the domain to exactly one element in the range. Functions are often represented using mappings or formulas.
For example, the function is defined by , , and . This function assigns a unique element from set to each element in set .
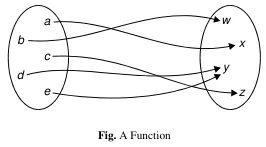
Source: Book page 12
Kind of functions:
-
Injection (one-to-one): A function in which each element in the domain is mapped to a unique element in the range. In other words, no two distinct elements in the domain are mapped to the same element in the range.
-
Surjection (onto): A function in which every element in the range is mapped to by at least one element in the domain. In other words, the range of the function covers the entire range.
-
Bijection (one-to-one and onto): A function that is both injective and surjective. In other words, it is a function where each element in the domain is mapped to a unique element in the codomain, and every element in the codomain is mapped to by exactly one element in the domain.
-
Invertible function: A function is invertible if there exist an inverse relation that maps from to .
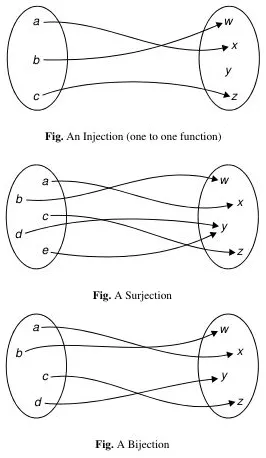
Source: Book page 12-13
Graphs
Section titled “Graphs”Formally, a graph is defined as a triple of , where is a finite set of objects called vertices, is another finite set of objects called edges, and is a function that assigns to each edge in a graph a subset , where and are vertices of the graph.
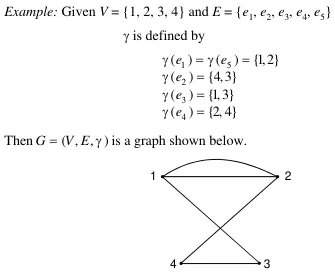
Source: Book page 15
See graph for terminologies and types of graph. In addition, we can say a graph is a tree if it is connected and has no simple cycles.
Strings & Languages
Section titled “Strings & Languages”A string is a finite sequence of symbols chosen from a given alphabet. An alphabet , denoted by is a finite set of symbols. The symbols can be characters, numbers, or any other discrete elements. For example, if we have consisting of the symbols , then “0101” and “111” are the example of strings over .
-
Length: The length of a string is the length of its sequence. The length of string is denoted as .
-
Empty string: A string with zero length, denoted as .
-
Reverse string: The reverse of a string. If , where each , then the reverse is .
-
Substring: A substring is a contiguous sequence of characters within a string. As an example, “deck” is a substring of “abcdeckabcjkl”.
-
Concatenation: An operation of combining them together to form a new string. Suppose string with length of and string with length of . The concatenation between them is written as , which is obtained by appending to the end of , that is .
In the case of concatenation of a string with itself, it is denoted as , where is the number of repetition. A concatenation of with empty string will be .
-
Prefix: Substring that appears at the beginning of the string. If for some , then is a suffix of .
-
Suffix: Substring that appears at the end of the string. If for some , then is a prefix of .
-
Lexicographical ordering: Lexicographical ordering is a way to compare strings based on their alphabetical order. For example, “apple” comes before “banana” and “01” comes before “10” in lexicographical ordering. The lexicographic ordering of all strings over the alphabet is .
-
Language: Formally, it is any set of strings over an alphabet. The set of all strings, including the empty string over an alphabet is denoted as . A language can consist of string that follows some property. Examples:
- . Language consist set of string that has the equal number of zeros and ones. For example, some strings that would belong to are “01”, “0011”, “1100”, “000111”, and so on.
- , where is the reverse string of . This language consist of string where its original is equal to its reverse (i.e., a palindrome, such as racecar, poop.).
-
Language with power: A language with a power , where describe the set of all strings of length under language .
- (consist of just empty string).
- .
- and so on…
We can also write , a set of all strings over an alphabet as (infinite).
-
Language concatenation: If and are languages over alphabet , their concatenation is written as , or simply , where .
For example, given ,
then . This is true because itself consist of even number of 0’s, concatenating it with , which mean adding 1 zero will make any language there have the odd number of zeros. -
Kleene Star: A language operation denoted as , which is the set of all strings obtained by concatenating zero or more strings from . More specifically, .
For example, from a language , we can form “110001110011”, since it can be formed by the concatenation of .
Boolean Logic
Section titled “Boolean Logic”See boolean logic.
Grammar
Section titled “Grammar”A grammar is simply a mechanism to describe a language, or specifically a set of production rules that describe the structure of a formal language. A grammar consists of a quadruple , where:
- : Finite set of objects called variables or non-terminal symbols. These symbols represent different syntactic categories or components that can be combined to form valid strings in the language. Examples of non-terminal symbols can include syntactic categories like noun, verb, sentence, or expression.
- or : Finite set of objects called terminal symbols. These symbols represent the basic building blocks or atomic units of the language. Terminals are the actual characters or tokens that appear in the strings of the language. Examples of terminal symbols include individual letters, digits, or punctuation marks.
- , in the form of : Finite set of productions rule. Each production rule specifies how a non-terminal symbol can be replaced by a sequence of terminals and non-terminals. It defines the valid ways to construct strings in the language.
- , where : A special non-terminal symbol that represents the starting point, called start variables. The goal is to generate valid strings in the language by repeatedly applying production rules, starting from the start symbol.
If we have a string in the form , and we apply the production rule , it means that we replace the substring in with the string to obtain a new string . We call a sequence of production rule applications that transforms the start symbol into a specific string a derivation.
Consider a grammar and . This expression represents the language generated by the grammar , comprising all strings that can be derived from the start symbol according to the production rules defined in .
- represents the set of all possible strings that can be formed using the terminal symbols .
- denotes that the start symbol can be derived or rewritten to produce the string using a sequence of production rule applications. The symbol indicates zero or more rewriting steps.
If a string belong to the grammar, or , then there exists a sequence , which is a sequence of production rule applications (or a derivation) that transforms the start symbol into the string .
During the derivation process, we call intermediate strings produced a sentential form. Therefore, with the string , we call a sentential form of the derivation.