Context-Free Grammar
Main Source:
- Book chapter 2
- Neso Academy playlist 65
- Neso Academy playlist 73-77
- Neso Academy playlist 78-81
- Neso Academy playlist 82-83
Context-free grammar is the grammar that generates context-free language, which is recognized by pushdown automata. The production rule is:
, where and .
Similar to the general and regular grammar, a non-terminal symbol can produce which can be any symbol from the set of all possible strings of symbols that can be generated using both the non-terminal symbols and the terminal symbols of the grammar, including the empty string.
From different sources, is sometimes used as . This implies that ( is equivalent with ).
The difference between regular grammar and context-free grammar lies in the production rules. Regular grammar is more restrictive, as the production rule must place non-terminal symbols either on the right or left side (i.e., non-terminals cannot be placed in the middle of the string). In contrast, context-free grammar allows the placement of non-terminals anywhere.
For example, the grammar is considered as a context-free grammar.
We can generate:
(by )
(by )
(by )
The language of this grammar will be in the form of .
Derivation Trees
Section titled “Derivation Trees”Also known as parse tree, it is an ordered rooted tree that graphically represent the derivation process of a context-free grammar. The five properties of derivation tree:
- The root of a derivation tree is .
- Every leaf node is a terminal symbol .
- Every vertex node is a non-terminal symbol in .
- When a vertex has a set of children labeled from , then vertex will have production rule in the form of .
- A leaf labeled with has no siblings, that is, a vertex with a child labeled can have no other children.
In other word, each level of the tree represents a step in the derivation process. Starting from the root, each level corresponds to the application of a production rule. The nodes at a particular level are derived from the nodes at the previous level.
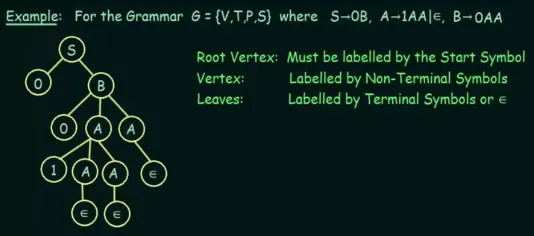
Source: https://youtu.be/u4-rpIlV9NI?si=mAYV4hyYXS9j7sfh&t=244
We see in the example that starting from , it produces terminal and non-terminal . We will make it as the child of , and continue the derivation process of . This is done for all production rule. If there exist multiple production rule for one non-terminal symbol, then we will have to use both of them in distinct node. When the production rule is recursive (i.e., ), we may stop the derivation and fill the leaf nodes with .
We also call any step of the derivation as a sentential form. A derivation tree in which the leaves contain a label from , or in other words, if any of the leaf still contains a non-terminal symbol, then the tree is said to be a partial derivation tree.
See also tree data structure.
is same as .
Left & Right Derivation
Section titled “Left & Right Derivation”When deriving a string with a grammar, there are two approaches, leftmost derivation and rightmost derivation. In leftmost derivation, the leftmost non-terminal in the current sentential form is always selected for expansion. While in the rightmost derivation, we select the rightmost non-terminal symbols. There is also mixed derivation, in which the two approaches is combined.
For example, a simple grammar with production rule , , .
Using this grammar, the string “ab” can be derived in the following ways:
- Leftmost Derivation:
- Rightmost Derivation:
Another example with the graphical derivation tree:
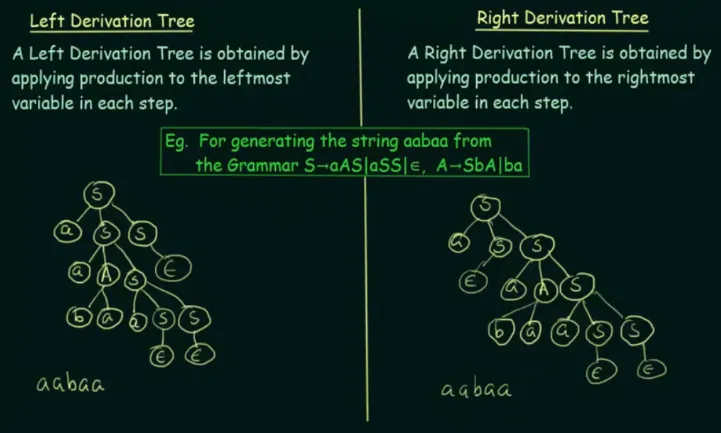
Source: https://youtu.be/u4-rpIlV9NI?si=mWlwEeGp_w5Ky123&t=740
In the left derivation process, we chose to apply the production rule , because applying the other rule would require us to replace . The production rule of involve occurrence of , if we use the production rule, we will have as the second character of the string (which is invalid). The process of derivation continues like this until we successfully create a parse tree with the correct characters combined from all the leaf nodes.
Parsing
Section titled “Parsing”Parsing is the process of finding a derivation for a string from a given grammar. It is a way to recognize a string and to determine if a string belong to the grammar.
The basic idea of parsing is, finding (or making) a parse tree. The manual way is to analyze a given string and the grammar, then carefully construct a parse tree (like what we did in the previous example above).
A brute force way of parsing, also called exhaustive search parsing involve generating all possible strings of the same length as the input and checking if any of them matches the input. This approach is obviously inefficient. A practical parsing algorithms would be designed to avoid exhaustive search by employing various optimization techniques.
Ambiguity
Section titled “Ambiguity”In parsing, ambiguity refers to a situation where a given grammar can produce more than one valid parse tree for a particular input string. Depending on which production rule is applied on each step, a different but valid parse tree could be generated.
The grammar generates strings having an equal number of “a“‘s and “b“‘s. The string “abab” can be generated in two distinct ways as shown in the following.
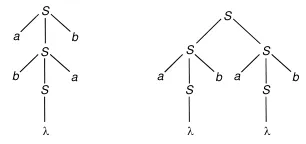
Source: Book page 129
Furthermore, the string “abab” has two distinct leftmost derivations:
And two distinct rightmost derivations:
Ambiguity can happen even in our daily lives, such as when encountering this ambiguous math expression “2 + 3 × 4”. Without parenthesis, it wouldn’t be clear in which order do we process this expression. We can interpret “2 + 3 × 4” as either “(2 + 3) × 4” or “2 + (3 × 4)”.
We will say a string that leads to this situation “ambiguously derivable”. A grammar is said to be ambiguous if there exists at least one string in which is ambiguously derivable. Ambiguity is a property of grammar, it is not always possible to find equivalent unambiguous grammar.
Simplification
Section titled “Simplification”The simplification of context-free grammar involves transforming or modifying the grammar to make it simpler or more manageable while preserving its language. This includes removing useless symbols, unreachable symbols, and simplifying the production rules.
For example, if we have production rule and , we can simplify this by directly substituting in the production rule. So, the simplified production rule is . This technique is also called substitution rule.
There are three steps in CFG simplification, reduction of CFG, removal of unit production, and removal of null production.
Reduction of CFG
Section titled “Reduction of CFG”The reduction involve eliminating useless symbols in the grammar, including non-terminals and terminals that do not contribute to generating any valid string in the language. It is divided into two phases.
- Removal of useless symbols, non-terminals and terminals that do not contribute to generating any valid string in the language.
- Removal of unreachable symbols, symbols that do not participate in the derivation of any sentential form.
A helpful procedure from the video:

Source: https://youtu.be/EF09zxzpVbk?si=qtn-ff6Wb-TJ2Zxv&t=323
With example grammar with production rules : , , , .
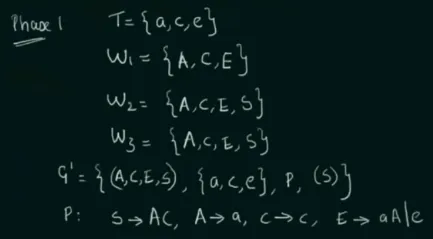
Source: https://youtu.be/EF09zxzpVbk?si=gc_WXN5N0yI5d6et&t=604
- Create a set that includes non-terminals that derives to some terminals.
- Create another set that includes non-terminals that derives to all symbol in the previous step.
- It is repeated until we obtained the same set in two consecutive steps (end at ).
- The new grammar will contain non-terminal symbols from the last set , and terminal symbols that are derived by those non-terminal symbols.
- A new production rule is created in which the symbol that doesn’t appear in the non-terminal of won’t be included. In the example, we see that we removed production rule , because itself doesn’t generate any terminal symbol (i.e., is a useless symbol).
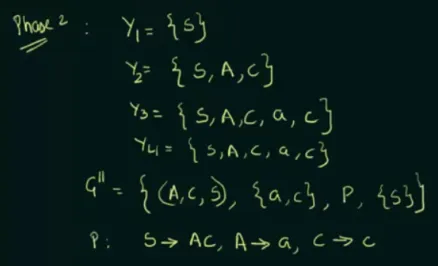
Source: https://youtu.be/EF09zxzpVbk?si=ra95MHcYogTYxDC9&t=779
- Create a set starting from the start symbol .
- Create another set that includes all the symbol (including non-terminals and terminals) that can be derived from the previous set.
- It is repeated until we obtained the same set in two consecutive steps (end in ).
- A new grammar we include the non-terminals and terminals from the last set .
- We will alter the production rule by only including those that are in the non-terminals of . In the example, we removed symbol entirely, because in fact no other symbol can reach it (i.e., is an unreachable symbol).
Removal of Unit Productions
Section titled “Removal of Unit Productions”Unit production refers to any production rule in the form , or a non-terminal that transform to another non-terminal. Unit production is sometimes redundant and can be simplified using substitution rule.
If production rule is in the form and there is a or a sequence of derivation that leads from to , then we can delete and replace it with .

Source: https://youtu.be/B2o75KpzfU4?si=NUhYWR4P7fznC6Lp&t=219

Source: https://youtu.be/B2o75KpzfU4?si=PYaESnF-Flc8mljR&t=493
The production rule involves a sequence of derivation from non-terminals to another non-terminals. We can substitute the final derivation step that derive to terminals to each sequence of derivation. Finally, we can remove all unreachable symbols.
Removal of Null Productions
Section titled “Removal of Null Productions”A null production is a production rule in the form of . If the variable doesn’t directly map to , this mean it needs a sequence of derivation , then we call the variable nullable.

Source: https://youtu.be/mlXYQ8ug2v4?si=i7_75uZdYmBzYOCL&t=131

Source: https://youtu.be/mlXYQ8ug2v4?si=sSOBcDT_ll4KWpl6&t=396
The first step is to remove all null productions from a variable and replace the variable occurrences in other production rules with epsilon. For example, we are going to remove first. contains 2 , and there is three possibility of removal. Changing the first to , so it becomes , changing the second to become , and changing both to be just . also appear in production rule of itself, and we can replace the in to to become just .
Next step is to remove all null production of , and obtain the simplified CFG.

Source: https://youtu.be/mlXYQ8ug2v4?si=7OuiYOepKinpa4z7&t=492
Normal Forms
Section titled “Normal Forms”A context-free grammar is said to be in normal forms when they follow specific structure or standards.
Chomsky Normal Form
Section titled “Chomsky Normal Form”Chomsky Normal Form (CNF) is when the context-free grammar follow the production rule in form:
- (where , , and are non-terminals)
- (where is a non-terminal and is a terminal)
- (where is the start symbol and represents the empty string)
In CNF, all production rules on the right-hand side should either be two non-terminals or a terminal, except for the rule allowing the start symbol to derive the empty string. Other standard are the elimination of unit productions and null productions, as well as the conversion of longer productions.

Source: https://youtu.be/Mh-UQVmAxnw?si=EZD7ndYRKnodk7mJ&t=143
The step 4 is a way to enforce maximum of two non-terminals on the right-hand side. It is done by adding another non-terminals that has the same production rule. For example, instead of , we can add that , and change to .
Additionally, when a production rule contains both non-terminal and terminal symbols simultaneously, we can follow the step 5. The step 5 shows that we can separate non-terminal and a terminal by making another non-terminal that produce the terminal.
Example
Section titled “Example”
Source: https://youtu.be/FNPSlnj3Vt0?si=Ao7POmbn_eLJCk1O&t=725
- Start symbol can’t appear on the right-hand side, so we can make a new start symbol that produce .
- Removing null production by following this.
- Removing unit production by following this.
- A new non-terminal is added here.
- is added to replace that is combined with .
Greibach Normal Form
Section titled “Greibach Normal Form”In Greibach Normal Form (GNF), every production rule in the grammar is in the form:
- (where is a non-terminal, is a terminal, and is a possibly empty sequence of non-terminals)
The right-hand side of the production rule starts with a terminal symbol, followed by a sequence of non-terminals.

Source: https://youtu.be/ZCbJan6CGNM?si=pS0u9kuYGdlGbHC8&t=758
In order to convert from CFG to GNF, we have to convert it to CNF first. If CNF restrict the length of right-hand side of a production, GNF allows for longer right-hand sides compared to CNF.
Example
Section titled “Example”
Source: https://youtu.be/ZCbJan6CGNM?si=DiBqkV6DAv0zHJwb&t=767
- Keep in mind that we have to confirm it is in CNF first. The step 3 told us to change the name of non-terminals to numbered , such as .
- The production rule will be altered so that the numbering in left-hand side is always lower than the right-hand side.

https://youtu.be/rauqqM0nfuI?si=FplhJA1avFCa6QsS&t=294
- A left recursion is when non-terminal on the left-hand side of a production rule appears as the first symbol on the right-hand side. Removing left recursion involve adding new variable to remove it. Upon adding the new variable, we will rewrite the production rule twice. The first time will be same, following the old , the second time will be rewriting but adding the new variable to each production rule.

Source: https://youtu.be/rauqqM0nfuI?si=cSCk3rJx4KJAg9KT&t=633
- After altering , there is still a problem, a non-terminal symbol appears as the first element on the right-hand side of the production rule for . The can be replaced to . Then, the first in is substituted with the whole production rule. For example, the first is changed to and then added with the second. Next, is replaced again with and added with the second , and so on for each production rule in .
- There is also a problem in , we also address this by doing the similar thing.
Pumping Lemma for Context-Free Languages
Section titled “Pumping Lemma for Context-Free Languages”Pumping lemma for context-free languages is to prove that a language is not context-free. In contrast, pumping lemma for regular language proves that a language is not regular.
The lemma states:
Any context-free language has a pumping length , such that any string in , where can be divided into five parts: , satisfying the following conditions:
- is in for every
Similar to the previous pumping lemma, it is a proof based on contradiction. A helpful procedure from the video:

Source: https://youtu.be/jRhqx1_KcCk?si=PQWy2IpLX7wc_wfp&t=259
Example
Section titled “Example”
Source: https://youtu.be/eQ0XkUk3qGk?si=2DO7eT_GCWy0jLFQ&t=429
- Pick a pumping length and a string . is chosen to be 4 and , so .

Source: https://youtu.be/eQ0XkUk3qGk?si=RyCf4AbLvHGW-yxr&t=700
- Consider some case of language such that for some . Remember that the language must be in the form of according to the original language.
- It is shown that in either two case, both fail to satisfy the three pumping lemma condition at the same time, so the language is proven to not be a context-free.