Markov Decision Process
Main Source:
Markov Decision Process (MDP) is a mathematical framework used to model sequential stochastic decision-making problems. MDP extends Markov chain to include decision-making, actions, and rewards. Similar to Markov chains, the decision-making process in MDP is operated in a discrete time step.
The environment in a reinforcement learning problem can be modeled in MDP, it will be a stochastic environment where the transition is influenced by probabilistic transitions. The agent that operates in the environment will observe the current state and select which action to take. The environment then transitions to a new state based on the chosen action, and the agent receives a reward or penalty associated with the state transition.
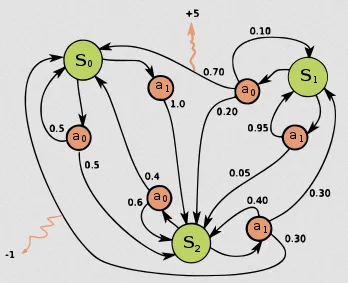
Source: https://en.wikipedia.org/wiki/Markov_decision_process
The image above shows an example of an MDP, the green circles are the states, orange circles are the actions, the number in black arrows are the probability of transitioning from one state to another when a specific action is taken, and the orange arrows are the reward and penalty.
For example if we are at state 1 (), we can choose to take action 0 () or action 1 (). Choosing action 0, there are 3 chances, we can either transition to state 2 () with 0.2 chance or back to state 1 with 0.1 chance or to state 0 (), which will give us reward of 5 in the chance of 0.7.
Component of MDP
Section titled “Component of MDP”An MDP contains four key component, they are represented in 4-tuple ():
- State space (): Represent all the possible state in the MDP
- Action space (): Represent all the possible action the agent can take. Alternatively, represent all the possible action from state .
- Transition Probabilities (): A function that defines the probability of transitioning from one state to another when a particular action a is taken. The function is defined as: , probability transitioning from state to state is equal to the probability of being in state at the next time step given that at current time step , the state is and action taken is .
- Reward Function: Which is a function defined as , it tells the reward or penalty received for transitioning from state to when action is chosen.
Last but not least, the policy function () (potentially probabilistic) which is a rule that tells the agent what action to take at some specific state.
Objective
Section titled “Objective”Similar to the main objective of RL, the optimization objective of MDP is to find an optimal policy that maximizes the expected cumulative rewards (return) over time. The return can be represented in value function which is a function that tells us the expected return an agent can obtain from a state under a given policy.
The formula are formulated in Bellman equation:
-
The first formula represent the value function update. According to the formula, when calculating the expected return from state , we consider the immediate reward received while transitioning to state from state , as well as the discounted future reward from . -
The second formula represent the policy function update. It will select the action that yields the highest return from the value function.
The goal is to find the best value and policy function. In order to achieve this goal, we employ these two formulas to iteratively estimates the value function and policy. The technique to approximate value function is also called value function approximation.
Value & Policy Iteration
Section titled “Value & Policy Iteration”Both value and policy iteration are the actual algorithm that uses the formula explained above to solve MDP by estimating the optimal function. It demonstrates dynamic programming or the technique to solve a problem by breaking it down into smaller subproblem.
The algorithm starts with an initial function and proceeds to iteratively compute it until reaching a point of convergence. The value of a state depends on another state, in other word, a problem depends on another problem, this can be referred as subproblem. This is where dynamic programming comes, we can start solving the subproblem first and then build up to the main problem. When we encounter a subproblem that has already been solved subproblem, we can efficiently use the information we have previously acquired.
The iteration involves updating the estimated value and policy based on the current estimate itself, this is known as bootstrapping