Neural Network
Main Source:
- Deep Learning Crash Course for Beginners — freeCodeCamp
- Backpropagation calculus | Chapter 4, Deep learning — 3Blue1Brown
- Softmax Activation Function — Developers Hutt
Neural Network Idea
Section titled “Neural Network Idea”In traditional machine learning, the features of the data need to be extracted manually by the researcher. The process involves extracting relevant features and identifying relationship or patterns. After that, the data with the corresponding feature can be feed to the machine learning model.
Neural Network is a method of machine learning inspired by the human brain to teach computer without needing much human assistance. Neural network is able to learn automatically and capture the relationship and underlying patterns in the data.
A neural network is built upon a mathematical function that takes input data. This function has variables or parameters called weights and biases, which are used with input data to somehow suit with the actual data to make prediction.
In high-level, the network processes the input data by calculating the mathematical function with the given weights and biases. The resulting output is then compared to the actual data. The network measures how wrong the predictions are and aims to minimize this error by adjusting the weights and biases. The adjustment can use algorithm like stochastic gradient descent.
To capture complex relationships and patterns in the data, the network utilizes activation functions. The process of calculating the mathematical function, utilizing activation functions, and adjusting the weights and biases is repeated multiple times during training. With each iteration, the network learns from its mistakes and updates the parameters to improve its predictions.
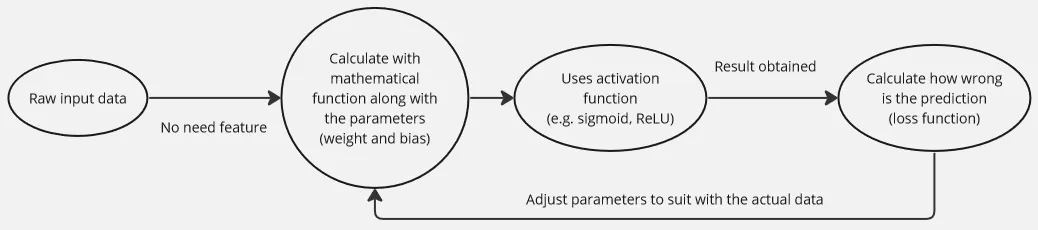
Neural Network Architecture
Section titled “Neural Network Architecture”Perceptron
Section titled “Perceptron”The simplest model of neural network is called perceptron, it consists of several input data and weights. The input will be calculated with their corresponding weight, summed up, and applied to an activation function to produce an output.
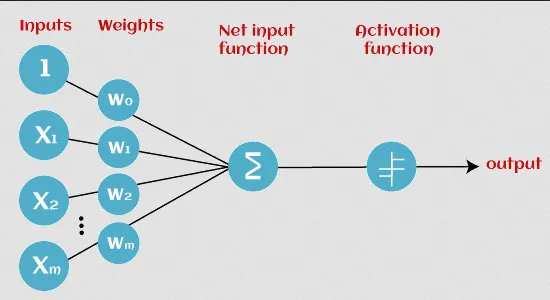
Source: https://www.javatpoint.com/perceptron-in-machine-learning
Multilayer Perceptron
Section titled “Multilayer Perceptron”Perceptron consists only a single layer, it only processes the input once. Multilayer perceptron (MLP) also known as fully connected feedforward network is similar to perceptron, however, it consists of multiple layers of processing. MLPs passes it through multiple layers with small units called neuron. Each neuron will be connected with each other.
The overall architecture consists of several layers of neuron, including input layer, hidden layer, and output layer. In MLP, information only flows in one direction, from the input layer to the hidden layer and finally to the output layer, without any loops.
-
Input Layer: The input layer receives the raw input data and passes it to next layer for further processing. The number of neuron in input layer represent the dimensionality of the input data.
-
Hidden Layers: Hidden layers are intermediate layer between input and output layer. The hidden layer is the actual process in neural network, it involves recognizing patterns of the data and using mathematical function as explained before. It also applies activation function to decide if a specific result of a particular neuron matters to the prediction or not. Number of hidden layers and neuron in each layer can vary depending on the complexity of the problem. For example,
-
Output Layer: The output layer produces the predictions based on the computations performed in the preceding layers. The number of neurons in the output layer depends on the nature of the task. For example, a binary classification task may have a single neuron in the output layer, representing yes or no.
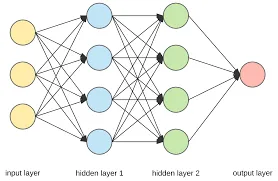
Neural Network Learning Process
Section titled “Neural Network Learning Process”Forward Propagation
Section titled “Forward Propagation”Forward Propagation is where the input data is processed and forwarded into hidden layer and finally to output layer. This involves calculating mathematical function with the input data. The mathematical function used is , where is the weight, the weight for each neuron can be different with each other, is input data except for the further layer, the is the result from previous layer, and is bias.
Basically the neuron in the front will receive input from all the neuron in the previous layer, it will use the above formula, multiply each input with weight and sum up all the result with additional value from bias.
The result is represented as :
After that, the (called weighted sum) will be applied to activation function resulting in another variable called : . The activation function can vary depending on the use case, for example, if we use sigmoid function: .
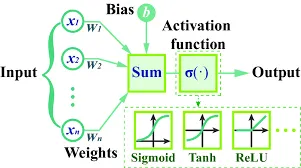
The weight is the coefficient of corresponding input data, it can be interpreted as how important is the neuron. The bias term is used to shift the activation function (similar to how we shift function in algebra), it controls how the function behave filtering a specific neuron.
Backpropagation
Section titled “Backpropagation”Backpropagation or backward pass is where all the learning process occurs. After getting result from all the preceding layers, the output layers is used to predict. The prediction will then be compared with actual data, the difference will be calculated in some loss function.
Same like traditional machine learning, we want to minimize the loss function, we can use the same principle as using gradient descent to minimize the loss in linear regression, where we calculate the gradient of the loss function with respect to slope and y-intercept. Remember that gradient shows us which direction to go to the minima of the loss function.
Backpropagation process is similar with some difference, it relies on principles of calculus, specifically the chain rule.
The gradient of loss function will be calculated with respect to weight and bias. The weight affects the variable before and the itself affects the variable which is applied to activation function. The variable is the output from the previous layer and used to predict, which means it affect the loss function and it is the actual things we take the gradient of.
This is where the chain rule comes, it allows us to decompose the contribution of weight to the loss function. The same also applies for calculating gradient of loss function with respect bias.
The output layer get its result from the preceding layer, it is affected by the previous layer. The previous layer itself is also based on the previous layer again, this is why its called backward pass, as it will adjust each weight and biases on each neuron of the preceding layers.
After calculating the gradient, now it’s time to adjust of weight and bias. The adjustment is similar to the traditional linear regression, but now we adjust for weight and bias instead of slope and y-intercept. We can also use algorithm like stochastic gradient descent.
For example, after predicting, the loss function calculated results in a large value. The loss function is affected by specific neuron on the previous layer, basically that particular neuron “messed up” our prediction. By calculating the gradient of weight and bias and adjusting it based on the optimization algorithm, we can controls the behavior of that particular neuron. We can make the weight smaller to indicate that neuron shouldn’t contribute much to our prediction or we can adjust the bias so that the activation function can decide whether to contribute the output of that neuron to the next layers or not.
This learning process will be repeated for many times based on the hyperparameter (e.g. batch, epoch, iteration).
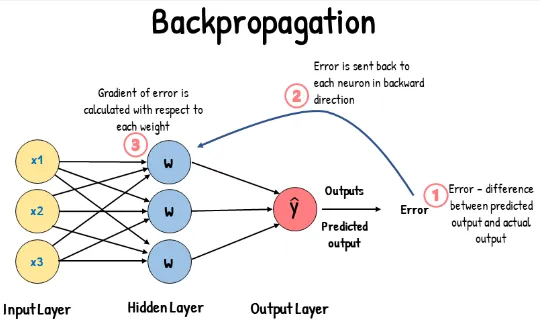
Vanishing Gradient Problem
Section titled “Vanishing Gradient Problem”Vanishing gradient problem is a phenomenon occurs in backpropagation due to it’s nature of calculation.
In backpropagation, gradient of loss function is calculated starting from the output layer, it will then be propagated backward. With the chain rule, the gradient will keep being multiplied with the previous layer and their value might become small and smaller as we keep multiplying them together.
A smaller gradient can cause a slower learning because the updates to the weight and bias are going to be small. One of the way to help mitigate vanishing gradient problem is to use a correct activation function such as ReLU and its variant. ReLU helps preventing the gradient from becoming too small because it doesn’t saturate the positive region compared to other activation function like sigmoid that saturate at large and negative values.
Softmax Activation Function
Section titled “Softmax Activation Function”Softmax is an activation function typically used in multi-class classification problem. It is a mathematical function used to assign probability to each class, the highest probability is the one our model will predict.
The formula for softmax is:
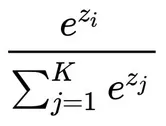
Source: https://towardsdatascience.com/softmax-activation-function-explained-a7e1bc3ad60
Where:
: output for i-th class
: the number of class
: output from j-th class, will be summed up with all the output
Softmax is typically used as the activation function for the output layer of neural network. Output will be produced after processing the input from all the preceding layer. The result will be calculated using the above formula.
The formula will produce probability for a particular class by dividing the result of that class from preceding layer with sum of all result from all output neuron.
For example, consider a scenario where we have 4 class classification task.
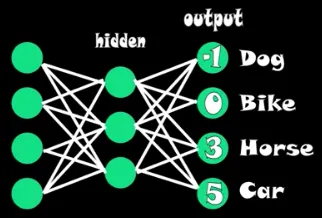
Source: https://youtu.be/8ah-qhvaQqU?si=llIp3EluG-zh3gjX&t=80
After processing through all the layers, each output layer produces an output. The denominator is the sum of constants raised to each output value. Therefore, it will be = .
To assign probability to each class, we will use that particular class output as the numerator.

Source: https://youtu.be/8ah-qhvaQqU?si=3ogI3IgJnZZXLkZC&t=103
And the highest probability is the one that the model believes to be the most likely prediction for the given input.