Linear Regression
Main Source:
- The Mathematics of Machine Learning — Zach Star
- Multivariable Calculus Gradient Descent — Khan Academy
Linear Regression Idea
Section titled “Linear Regression Idea”Linear Regression is a statistical technique used to model and predict between dependent and independent variable. Dependent variable is a variable that we are going to measure or predict while independent variable is the one we thought is going to affect the dependent variable. In other word, we believe that it has impact or influence to variable we are going to measure.
In linear regression, we believe that there is a linear relationship between the dependent and independent variable, this means that as one variable change, the other will also change, the change will be consistent and propotional.
For example, in real scenario, as a house area getting larger, it make sense that the price will be more expensive. In this case, house area and house price has a positive relationship. If we know for sure the relationship between dependent and independent variable, we can predict what will happen next when a variable (typically the independent variable) change.
In linear regression, we predict the outcome of dependent variable by drawing a line. The line should be as fit as possible to the data we know before. This line act as a “standard” that capture the relationship between dependent and independent variable. With this standard, we can predict what is the outcome of dependent variable in some independent variable.
Example
Section titled “Example”Before starting, we will need a dataset that consist of known dependent variable with its independent variable.
Consider the image below, after gathering enough data, we plot them all in a graph (denoted as blue point). For example, when the independent variable () is equal to approximately 3.5, the dependent variable () is approximately 2.1. After plotting all the data, we will try to construct a line. The line should be as representative as possible.
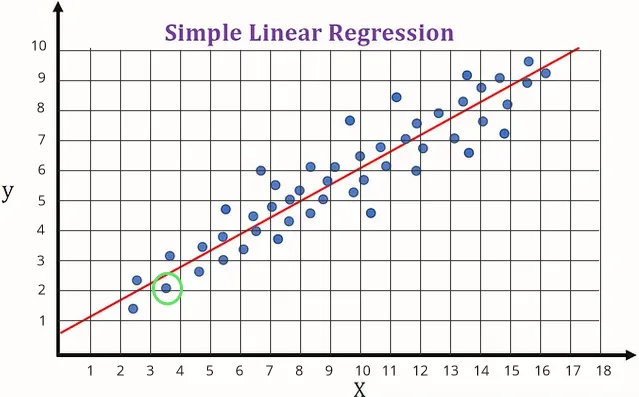
Source: https://saichandra1199.medium.com/linear-regression-1e279814e2bb (with modification)
Using the data, we know that typically a lower value will also result in lower value and the higher will result in higher . By plotting these data and drawing a line, we can predict easier. The line is a mathematical model, meaning that we use mathematical equation or notation to model a real life situation.
A straight line typically modeled by: , where is slope of line, is y-intercept. The is the dependent variable we are going to find out and the is the independent variable.
So if we want to know a value for a particular value, we can use the line as a standard to predict the outcomes. Using the line equation, we can just plug in an value together with the equation of line we construct and we will get the value.
This will not work if our data has no linear relationship, also the more data we have will result in better prediction as we will be able to capture more relationship about the variable.
More Detailed Explanation
Section titled “More Detailed Explanation”The goal of regression is to construct a line that fit the data as fit as possible to predict the next outcomes. Here is an example of data plotted on a graph.
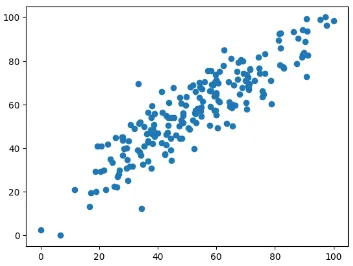
By just seeing it, indeed there is a positive linear relationship between the x-axis and y-axis value. Next, we will draw a line that act as the standard for the prediction. We could make any line we want like the image below:
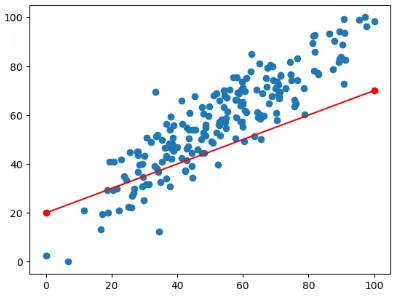
But this will probably result in bad prediction, the difference between the actual data (blue points) and the prediction data (anything that lies on the line) is kinda large. The difference between these are called error.
The error is calculated by calculating the difference between actual data and prediction data. These error will be summed up for each points. Error is used to measure how bad or good a regression line is, the more error means the worse line.
So we would want a line with less error like this:
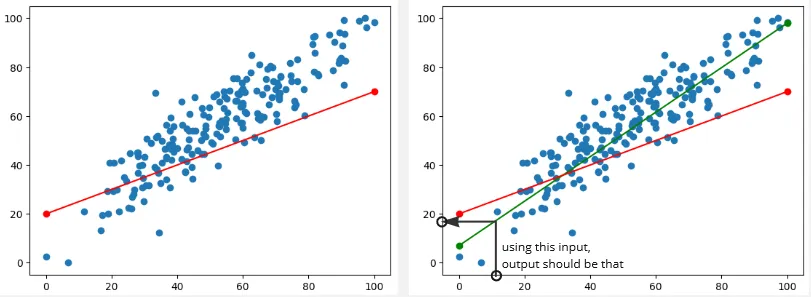
By the way, when the predicted value is lower than the actual value, its called Underestimation. On the opposite, overestimation happens when the predicted or estimated value is higher than the actual value.
Minimizing Error
Section titled “Minimizing Error”For simplicity, we will use a simpler data and we will ignore the y-intercept for now, we will just use the slope to make the line.

Source: https://youtu.be/Rt6beTKDtqY?si=heJuep-IpaK_V6ki&t=108
The approach of fitting the best line is to try to draw a line with particular slope and calculate the error to see how it performs. We keep trying this for a several times, the result can be visualized where the x-axis is the particular slope of the line and the y-axis is the error. If we see the graph, the smallest possible error we can get is by drawing a line with a slope of 1.68.
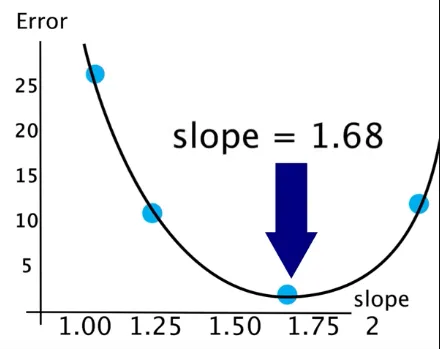
Source: https://youtu.be/Rt6beTKDtqY?si=9_O7XygkvOvZRjiq&t=202
This approach sounds good, but how do we know what slope to try next? Also, in real case, we can’t visualize it as we need to try a bunch of times to be able to draw a perfect graph like above. This makes us not sure if increasing or decreasing slope will decrease the error or not.
The point of this is to find the corresponding x value for the minimum y value. Mathematically speaking, we are trying to find the minima of a function. The concept of minima is often used in optimization problems, where the goal is to find the input value(s) that minimize a given function. The commonly used technique to minimize the error in linear regression and other machine learning technique is the Gradient Descent algorithm.
Gradient Descent
Section titled “Gradient Descent”Gradient descent is an iterative algorithm used to find optimal coefficient value such as the slope of the line in linear regression, it aims to minimize the error or the cost function.
The concept of gradient descent comes from calculus, where we find the critical points of a function that may be local minima, local maxima, or a saddle point when the derivatives of the function is equal to zero.
So we will need a function to do that, in this case the function may look like the image above, where we graph the slope in x axis and the corresponding error in the y axis. However, we can’t guarantee it will be easy for us to capture the function as formula and to solve the function derivative equal at 0. Instead we will try to approximate the actual solution, gradient descent is such the method. Gradient descent can be thought as the numerical method for finding critical points of a function.
The derivative of a function shows the function behavior at that point, the positive derivative means that the function is increasing. To find the minima, we will go to the opposite direction where the function is decreasing.
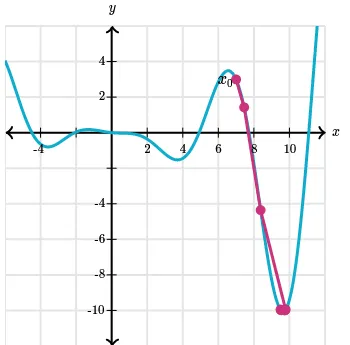
To use gradient descent for optimizing slope of a line, we can use the following formula:
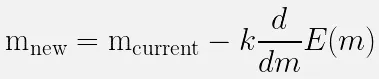
Where:
-
: new slope we will try next
-
: current slope
-
: step size or learning rate, used to measure of how far we want to go to the negative direction of function. The learning rate is very important, it affects the learning significantly. A smaller rate may slow down computation but a higher rate may make us “go to far” in the minimum direction.
-
: The derivative of the function , where itself is the error function we graphed before
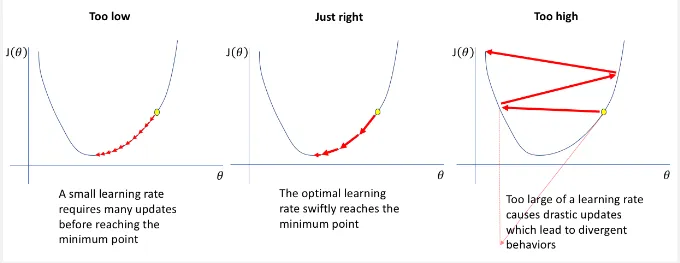
The subtraction between the slope and the derivative indicates that we are moving in the opposite (negative) direction of the derivative. The slope is gradually adjusted through iterations. The speed and effectiveness of the learning process can vary depending on factors such as the function, the data, and the learning rate. This variability can result in slow or fast learning and lead to either favorable or unfavorable outcomes.
After using gradient descent to optimize the slope, we may achieve a better fitting line. However, we can still improve this by also taking account the y-intercept of the line.
Gradient Descent in 3D
Section titled “Gradient Descent in 3D”If we also use y-intercept to draw the line and we want to optimize it aswell, we can do the same gradient descent method. This mean we will need to extend gradient descent method to 3D, because now we have two input which is the slope of the line and the y-intercept.
To extend gradient descent to 3D or higher multi-dimensional function, we will use the concept of gradient, which is the generalization concept of derivative in higher dimension, this mean we will use partial derivative instead. The positive gradient at a point tells us the direction of the steepest accent of the function at a given point. To find the minima, we would do the same, which is to go to the opposite direction of positive gradient or the negative gradient.
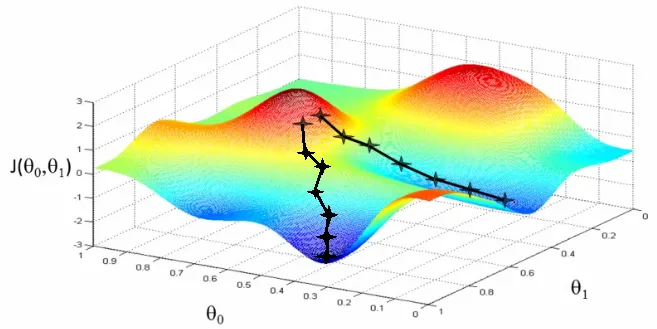
The formula now becomes:
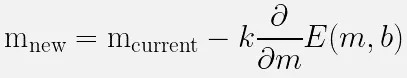
Where: b is y-intercept
Using gradient descent in 3D, we can know have more than 1 independent variable, we could have 10 variable that affects the dependent variable. For example, a house price may not only depends on area, it may depends on location, how much beds it has, and etc.
Other Regression
Section titled “Other Regression”There are various form of regression along with the optimization and the cost function used. An example is:
-
Polynomial Regression: Polynomial regression is the form of linear regression where the relationship between the variables are not linear, instead it is a form of polynomial function such as curves.
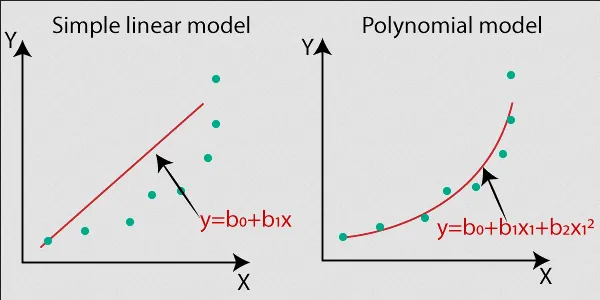
Source: https://www.javatpoint.com/machine-learning-polynomial-regression