Reinforcement Learning Fundamental
Main Source:
- Introduction To RL — OpenAI Spinning Up
- An introduction to Reinforcement Learning — Arxiv Insights
- Reinforcement Learning – Exploration vs Exploitation Tradeoff — AI ML Analytics
- Solving the Multi-Armed Bandit Problem by Anson Wong — Medium
Reinforcement Learning (RL) is one of the three machine learning paradigm alongside supervised learning and unsupervised learning. In RL, we do not teach the model how to perform a task directly by providing labeled examples (supervised learning) or by discovering patterns in unlabeled data (unsupervised learning).
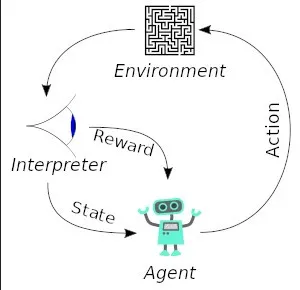
The machine learning model, called agent needs to learn the environment by taking action and receiving feedback. The learning process in RL involves trial and error. The agent initially has no knowledge about the environment and randomly explores different actions. There will be reward and penalty as the positive or the negative feedback. The objective of RL is to maximize the reward while also adhering to any specified regulations or constraints.
In summary, we do not explicitly teach the model or agent. Instead, we allow the agent to explore and learn on its own. To guide the agent towards specific tasks, we provide rules or guidelines and provide feedback based on its actions.
A simple example for RL problem is solving a maze. The objective is to find the optimal path from start to the end. A state correspond to the location of agent in the maze. The action is the direction to move (e.g. left, right, down, up). The positive reward is when the agent reaches the goal while the negative reward is when it hits a wall or takes a suboptimal path.
Source: https://neptune.ai/blog/reinforcement-learning-applications
Terminology
Section titled “Terminology”Agent is the machine learning model or the entity that make decision and interacts with environment. The agent’s actions are influenced by its current state, which represents the information it has about the environment at a given time.
Environment
Section titled “Environment”Environment is the world or system in which RL agent operates. It can be a real-world or a simulated environment. The environment should have well-defined state, action, and reward to ensure the learning efficiency of the agent.
An environment can also be stochastic, which means it doesn’t entirely depend on the current state and action, it involves element of randomness or uncertainty.
State, denoted as is the condition of the environment at a particular time. It contains all the information about the environment such as the agent’s location. While a state represent complete condition, an observation is a partial representation of that state, it can be a sensor measurement in a robotics problem.
A state can be discrete or continuous. A discrete or categorical state can be the coordinates of the agent’s position in the grid of maze. A continuous state can be found in a robotic problem such as joint angles, end-effector position, and velocities.
Action
Section titled “Action”Action, denoted as is the choice or decision made by agent to interact with the environment. The action done by agent will influence the state of the environment.
A set of all valid action in a given environment is called action space. Similar to state, action can also be discrete or continuous. For example, we can move discretely in a grid-based task like maze or move continuously in a self-driving car task, where the action space could be the steering angle of the car.
Policy
Section titled “Policy”A policy is a strategy or instructions that guide an RL agent to make decisions. It determines the agent’s behavior by specifying which actions it should take in different situations or states. Policy is defined as a function that takes a state and returns an action.
A policy can be deterministic or stochastic:
- Deterministic: A deterministic policy maps a state directly to specific actions, it is represented as . This mean, according to the policy if we are at state , we need to take action .
- Stochastic: A stochastic policy gives different action in a probabilistic manner based on the given state, it is represented as . The means we are randomly selection an action from a probability distribution given by the policy function , conditioned on state . The dot here is a placeholder for an action variable.
Policy act as a brain for the agent, it will keep being updated to adjust with the environment so that it can guide the agent toward best result.
Here is an example of a stochastic policy for a specific state:
The policy act as the rules for agent to select an action. The action of the agent will be randomly sampled from these policy. So, when the agent is at state , it may sample or select one of these four.
In the context of deep RL algorithm, where we utilize parameters of neural network (e.g. weight and bias), we can set the policy as a learnable parameter. The parameters are often denoted as or and then it will be written on the policy’s subscript (e.g. ).
Trajectory
Section titled “Trajectory”A trajectory is a sequence of state and action that an agent experiences while interacting with an environment. It is denoted as , where and are state and action, respectively. The very first state is randomly sampled from , which is the initial state distribution
The movement from one state to another is called a state transition. A state transition is described by a transition function, together they are denoted as , this means the next state is given by the transition function (depends on the problem) which takes current state and action.
The state transition can also be stochastic: , when the agent takes a particular action in a given state, there is a probability distribution over the possible resulting states.
Reward, Return & Horizon
Section titled “Reward, Return & Horizon”Reward serves as a value that provides feedback indicating the quality of its action. It is determined by the reward function: (state-based reward) or (state-action-based reward). This mean the reward at time is determined by the reward function that takes either current state only or takes both current state and action.
The return, also known as cumulative reward or the discounted sum of future rewards, is the total amount of rewards the agent accumulated over a time horizon. A horizon is a predetermined length or number of time steps in an episode or a task. An episode is a complete sequence of interactions between an agent and its environment.
A horizon represents the limit or duration of the agent’s interaction with the environment. It can be finite, meaning there is a fixed number of time steps until the end of the episode, or it can be infinite, allowing the interaction to continue indefinitely.
-
Finite-Horizon Undiscounted Return: In the case of a finite horizon, the agent’s objective is to maximize the undiscounted return. The undiscounted return is the sum of rewards obtained from the current time step until the end of the episode, without any discounting factor applied.
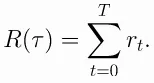
Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#reward-and-return -
Infinite-Horizon Discounted Return: When the horizon is infinite, the agent’s objective is to maximize the discounted return. The discounted return is the sum of rewards obtained from the current time step until infinity, but each reward is discounted by a factor (\gamma) (gamma) between 0 and 1. The gamma will be raised to the power of , which causes it to decrease as increases.
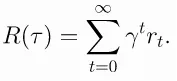
Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#reward-and-return
Both have the same purpose, which is to maximize return, they differ in the use of discount factor. The discount factor introduces a trade-off between immediate and future rewards, serving as a balancing mechanism. The agent can choose to prioritize obtaining high reward to minimize the impact of the discount factor or delay the rewards in the risk of large discount amount.
RL Main Objective
Section titled “RL Main Objective”The main goal of RL is to maximize the expected cumulative return or total reward obtained by an agent over time. Combining all together, we can construct the following formula:

Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#the-rl-problem
The represent the trajectory or event that will occurs (in probability distribution) given that a policy applies. It is obtained by the product of the very first state with initial the state multiplied with the product of each state transition () with the policy () from time step 0 to .
The is the expected return, it represents the expected cumulative reward that an agent will receive when following a specific policy over an extended period of time.
And the last expression basically means that we are looking for optimal policy that yields the highest expected return among all possible policies .
Value Function
Section titled “Value Function”Value function is a function that assigns a value to each state or state-action pair, the value represent the expected return an agent can obtain from that state or state-action pair under a given policy.
There are four main value function:
- On-Policy Value Function (V-function): It describe the value that agent can obtain when starting in state and following a particular policy.
- On-Policy Action-Value Function (Q-function): It describe the value that agent can obtain when starting in state , taking action , and following a particular policy.
- Optimal Value Function (-function): The optimal or maximum of V-function.
- Optimal Action-Value Function (-function): The optimal or maximum of Q-function.

Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#value-functions
In practice, the value function is usually not known to us. There are several reasons for this:
- Complex or Unknown Environment: It is often impossible to have complete knowledge of all possible states, actions, rewards, and transition dynamics.
- Sparse Rewards: Sometimes, the reward is not directly given to the agent after doing an action, if the agent doesn’t receive any feedback after a long time, it may lead to difficulties in finding the optimal policy. A reward that is too high or too low can also make the learning unstable.
- Stochasticity: Many environments are stochastic, meaning that the outcomes of actions are subject to randomness which makes it difficult to predict the exact reward or value for a state because it can vary from one interaction to another.
Bellman Equation
Section titled “Bellman Equation”Bellman equation is an equation, typically used in dynamic programming, it is an equation that decompose a problem into smaller subproblems and finding the optimal solution by iteratively updating the value.
In the context of RL, Bellman equation is applied to describe how the value of a state (or state-action pair) is related to the values of its successor states. It says that the value of a state is the reward for current state plus the discounted value for next state. The value for the next state also depends on the next and next state, making it a recursive equation.
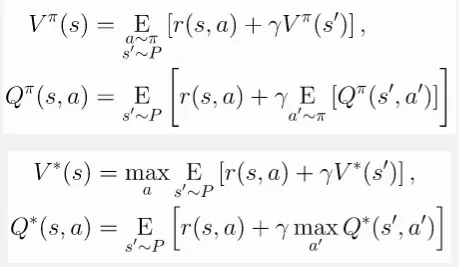
Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#bellman-equations
Bellman equation provides a mathematical framework to model the values of states or state-action pairs in reinforcement learning. We can compute the value iteratively and the agents can adjust their estimates of the value of states by considering the rewards they have observed so far and the values of the states that follow.
Advantage Function
Section titled “Advantage Function”Advantage function is a function that estimate the advantage or benefit of taking a particular action in a given state compared to other actions corresponding to a policy. It measures the relative value of an action with respect to the value function.
![]()
Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro.html#advantage-functions
The represent the advantage of taking action in state . A positive advantage indicates that the action is better than average, while a negative advantage suggests that the action is worse than average. A value close to zero means the action is roughly equivalent to the average.
Conclusion
Section titled “Conclusion”The stochastic aspect along with reward and penalty terms on each action in reinforcement learning makes it different with supervised or unsupervised learning. In the latter two machine learning paradigms, the model always choose the highest probability based on the data they learned (e.g. while predicting or classifying). However, in reinforcement learning, even if we have high probability we will always try to explore different choice and reward. This enables reinforcement learning model to adapt itself with the environment, without needing an explicit instruction or example on a specific tasks.
Model-Based & Model-Free
Section titled “Model-Based & Model-Free”Model-Based and Model-Free are the two approach of reinforcement learning.
-
Model-Based: In model-based RL, the agent has access to a model of the environment. Model of an environment is a simulation of the environment in which an agent operates. It provides information about the dynamics of the environment, including transition probabilities and rewards. The agent uses this model to simulate the environment and plan its actions. The use of model is to enable the agent to simulate and plan ahead before actually taking actions.
-
Model-Free: In model-free RL, the agent does not have access to the model of the environment. Instead, it learns directly from interacting with the environment without prior knowledge of the transition probabilities and rewards. Model-free RL algorithms learn by trial and error, exploring the environment and updating their policy or value estimates based on observed rewards. They aim to find an optimal policy or value function that guides them toward the best return.
Exploration & Exploitation
Section titled “Exploration & Exploitation”Exploration and Exploitation is a common dilemma in reinforcement learning.
-
Exploration: Refers to the process of seeking out and gathering new information about the environment. By exploring, it means the agent takes action that isn’t considered the best according to the current policy. The agent explores to potentially finds better actions or states that may lead to higher rewards.
-
Exploitation: Exploitation is often referred as the “greedy” technique that prioritize immediate rewards or maximize the cumulative rewards based on the agent’s current policy. In other word, the agent will choose actions that yield the highest reward according to current policy.
Both strategy is very important in machine learning, we need to balance the exploration and exploitation. Too much exploration may lead to excessive randomness and inefficient use of learned knowledge, while too much exploitation may result in the agent getting stuck in a suboptimal policy and missing out on better opportunities.
Epsilon-Greedy
Section titled “Epsilon-Greedy”Epsilon-greedy is a common strategy used in reinforcement learning to balance exploration and exploitation. The balancing is determined by probabilities, which is set by the epsilon () parameter.
First, we choose the value of epsilon (), the epsilon represent the probability of exploring, the exploration include selecting random action. The probability to exploit is determined by 1 - , the agent will select the highest estimated value based on its current policy.
A higher value of encourages more exploration, while a lower value of favors exploitation. The can be decreased gradually, over time, the agent can transition from initially exploring extensively to eventually exploiting the learned knowledge more frequently.