Semantic Analysis
Main Source:
- Book 1 chapter 6, 7
- Book 2 chapter 4
- Compilation - Part Three: Syntax Analysis — Computer Science
- Symbol table — Wikipedia
- What is the purpose of a symbol table in a compiler? — Linkedin
Abstract Syntax Tree
Section titled “Abstract Syntax Tree”Abstract syntax tree (AST) or syntax tree represent syntactic structure of the input language. It is the simpler and more abstract version of parse tree (also known as concrete syntax tree), both are typically produced after syntax analysis (parsing) process. Compiler may choose to directly create AST instead of parse tree.
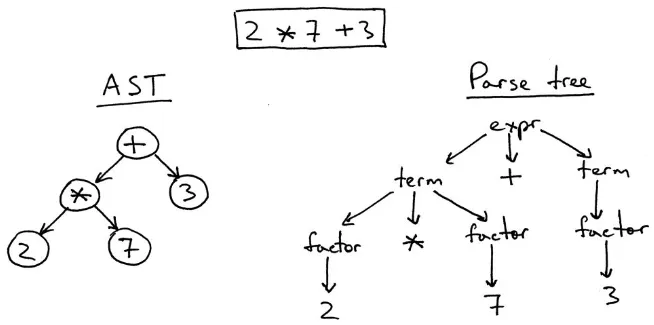
Source: https://ruslanspivak.com/lsbasi-part7/
The AST contains only the necessary information for code generation. It doesn’t include explicit grammatical information or unnecessary tokens like parentheses. The tree structure is arranged in such a way that it preserves the same without these.
In the compilation process, the AST is used to keep track of syntactical information. It is a data structure used by the compiler to generate code later on. Sometimes, it is transformed into an intermediate representation first, then into real machine code. The AST is frequently represented as linked structure, such as linked list, tree, or graph structure.
AST Representation in Code
Section titled “AST Representation in Code”Declarations
Section titled “Declarations”Consider a programming language, below are valid declarations in the language.
b: boolean;s: string = "hello";f: function integer ( x: integer ) = { return x * x; }Under the hood, we can represent source code that declare something with a decl structure which has several properties.
struct decl { char *name; struct type *type; struct expr *value; struct stmt *code; struct decl *next;}It has the variable name, type, value (if an expression), code (if a function), and a pointer to the next declaration in the program. All of them holds reference to another structs. If specific record doesn’t hold anything, it should be null.
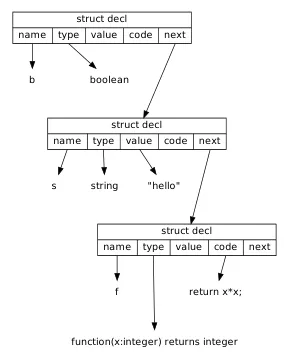
Source: Book 1 page 87
Using this, we effectively created a linked list with hierarchical and linked structure of declarations.
Statements
Section titled “Statements”Statements can be represented with:
struct stmt { stmt_t kind; struct decl *decl; struct expr *init_expr; struct expr *expr; struct expr *next_expr; struct stmt *body; struct stmt *else_body; struct stmt *next;}
typedef enum { STMT_DECL, STMT_EXPR, STMT_IF_ELSE, STMT_FOR, STMT_PRINT, STMT_RETURN, STMT_BLOCK} stmt_t;We also associate statement with type, such as declaration, expression, if-else, for-loop, etc. A statement also has various field, such as its initialize expression, statement body, and an else body for if-else statement. They also hold reference to the next statements and expressions.
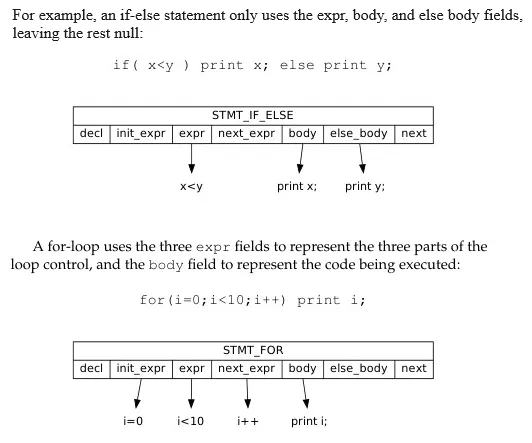
Source: Book 1 page 89 (added with custom text)
Expressions
Section titled “Expressions”An expression can be evaluated from left and right based on precedence, so we will need a reference to its left and right.
struct expr { expr_t kind; struct expr *left; struct expr *right; const char *name; int integer_value; const char *string_literal;};
typedef enum { EXPR_ADD, EXPR_SUB, EXPR_MUL, EXPR_DIV, ... EXPR_NAME, EXPR_INTEGER_LITERAL, EXPR_STRING_LITERAL} expr_tAn expression have kind,
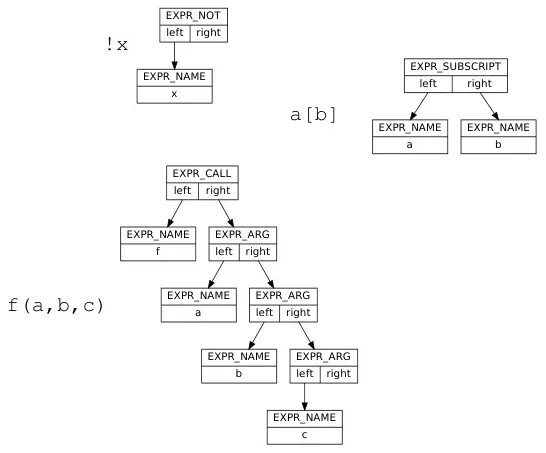
Source: Book 1 page 91, 92
These expressions have arguments, which are the operands. The type of function/operator is described in kind, such as add operation, subtract, multiplication, etc. An EXPR_NOT describe a unary NOT operation, its argument is typically placed on the left. We can also use the left and right argument as a way to put function arguments. They are described by chaining several EXPR_ARG nodes.
A data type structure contains kind, subtype, and params.
typedef enum { TYPE_VOID, TYPE_BOOLEAN, TYPE_CHARACTER, TYPE_INTEGER, TYPE_STRING, TYPE_ARRAY, TYPE_FUNCTION} type_t;
struct type { type_t kind; struct type *subtype; struct param_list *params;};
struct param_list { char *name; struct type *type; struct param_list *next;};A data type should have a field to describe what kind of type it is, a subtype which may be needed for compound types (types that contain another type), like arrays, and is used to describe the function’s return type; and a list of parameters which is used by the function.
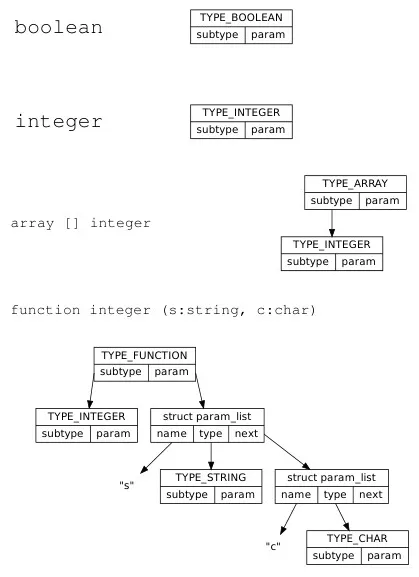
Source: Book 1 page 93, 94
- Primitive types are simply described from the
kindfield. - An array should have its subtype as the data type of the elements it contains. A nested array would contain another
TYPE_ARRAYas its subtype, which ultimately has the element data type. - The
param_listfor function would contain the name of parameter, the type, and a pointer to the next parameter.
Example Program
Section titled “Example Program”With the code:
compute: function integer ( x: integer ) = { i: integer; total: integer = 0;
for(i = 0; i < 10; i++) { total = total + i; } return total;}The AST would look like below.
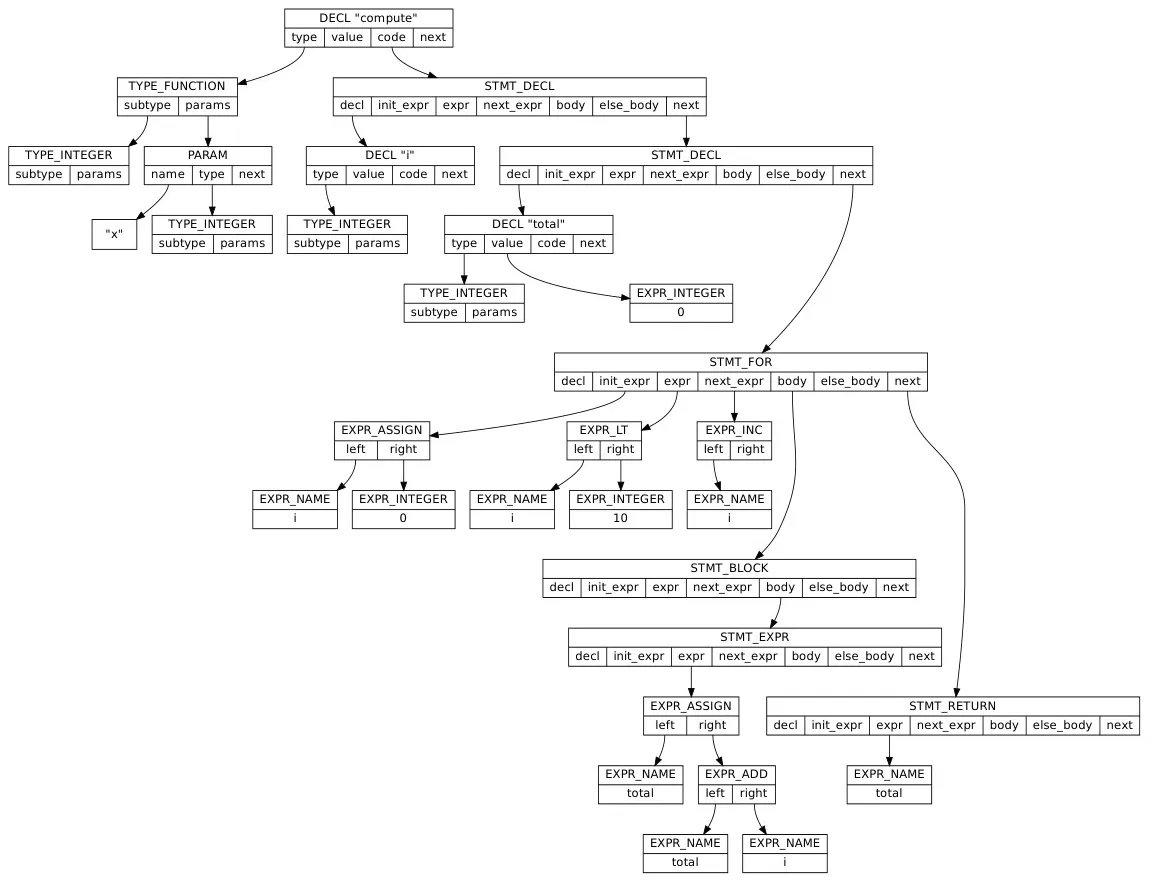
Source: Book 1 page 95
This AST would be constructed during parsing. For example, when a bottom-up parser reduces, it should append a node to the appropriate parent. The node would be a struct it has created beforehand. If it encounters if-else syntax, the struct would be a statement struct with the kind being STMT_IF_ELSE, and other fields would be specified depending on the circumstances.
Semantic Analysis
Section titled “Semantic Analysis”Semantic analysis takes AST and decorate it. This mean the structure of the grammar is added with additional semantic information to provide sufficient detail for generating intermediate or machine code.
Semantic analysis helps enforce programming language rules, which are typically specific to each language and cannot be captured in a parse tree with context-free grammar alone. This is because grammar is used to specify syntax rather than semantics. Semantics involve implementing type systems, checking declarations and usages of identifiers, etc.
Semantic analysis can be categorized into two types based on when it is applied: static semantic analysis and dynamic semantic analysis. The former occurs during compile-time, and the latter occurs during runtime. Some errors, such as the use of an identifier without prior declaration, can be identified at compile-time, while errors like division by zero are based on input, which is not known at compile-time.
Although, some tools may do semantic analysis during the time programmer write code (we can say during compile-time) to catch trivial or potential error as well as enforcing certain rules such as coding guidelines. The tools that do this in a way that they predict the runtime behavior are known as static analyzer.
Symbol Table
Section titled “Symbol Table”Semantic analysis may also involve looking up or adding information to the symbol table. The symbol table is a data structure used to store global information about identifiers (e.g., variables, functions, classes, etc.) encountered in the program.
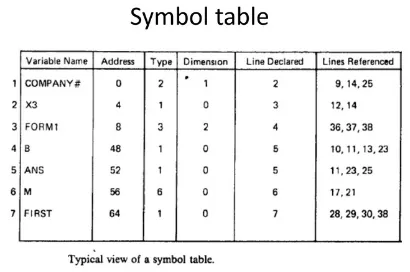
Source: https://www.slideshare.net/DrKuppusamyP/symbol-table-in-compiler-design
The symbol table is frequently accessed throughout many compilation steps. It is created during scanning and parsing. One common implementation for storing symbols is in a hash table. Each entry could be contained within a struct that has several properties commonly associated with an identifier, such as name, type, scope, memory location, etc.
With a hash table, a lookup with the variable name as the key could be made easily and quickly. Name resolution is the process of determining the correct declaration or definition of an identifier from symbol table based on the current scope and context of the program. One common approach to handle local and global scope is by nesting several symbol tables, where each table corresponds to a scope. This way, name resolution will always look to the nearest scope first.
Attribute Grammars
Section titled “Attribute Grammars”Attribute grammars are formal methods for specifying semantics of programming languages to a formal language like context-free grammar.
The production rule of context-free grammar are “decorated” with attributes, which are properties or values associated with the nodes (nonterminals and terminals) of the parse tree. Attributes can represent various information such as types, values, or intermediate results of computations. Association of semantic within the grammar allows us to perform semantic actions during parsing.
Below is an example of a grammar of arithmetic expressions in LR.
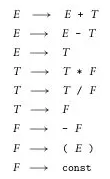
Source: Book 2 page 166
And the attribute grammar for the given grammars.

Source: Book 2 page 167
- Each symbol is numbered to be distinguished.
- Attribute grammar is written with equations that describe how can we describe the computation of attribute values. There are two types of attribute rules, copy rules and semantic function.
- Copy rules are attribute rule where one attribute is just a copy of another (e.g.,
E → T ▷ E.val:= T.val). - Semantic function is a function that describe an attribute value is computed with input of another attribute values. It can be any arbitrarily function the language designer want, and we can associate each non-terminal with a value. For example the describe the value of . The function may describe the sum of and .
- The value or function doesn’t actually have meaning, they are not fixed or standardized, but rather a convention that language designer adopt for clarity.
Attribute Evaluation
Section titled “Attribute Evaluation”The grammar is now associated with attributes, it is time to evaluate them. Attribute values are computed and passed from child nodes to parent nodes or from parent nodes to child nodes during the evaluation process. This is called evaluation flow.
Synthesize Attributes
Section titled “Synthesize Attributes”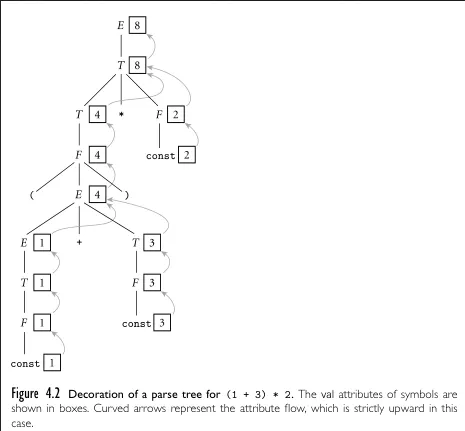
Source: Book 2 page 169
For this particular example, the flow of evaluation is bottom-to-up. We call attribute that are computed and passed up the parse tree from child nodes to parent nodes as synthesizes attributes.
When all attributes are synthesizes, such as our example above, we call it S-attributed. The property of S-attributed is, left-hand side is always produced by the right-hand side. This is true for all attribute in the attribute grammar. This property makes each node in the decorated parse tree to obtain value from their child nodes, causing the tree to be evaluated bottom-to-up.
Inherited Attributes
Section titled “Inherited Attributes”The opposite, where information is allowed to pass from parent nodes or side nodes are called inherited attributes. Below is an example where bottom-up evaluation is not possible due to subtraction, in which its mathematical property is left-associative (i.e., have to be evaluated from left).
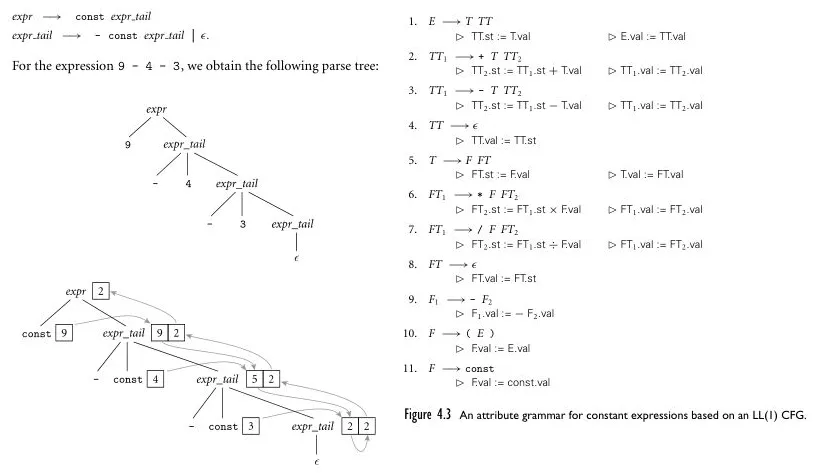
Source: Book 2 page 169-171
From the left child of expr it is passed to its sibling node, namely expr_tail and so on until the bottom most node. Then, the result (2) goes back to the root.
When all attributes are evaluated from left-to-right like this example, it is called L-attributed grammar.
An attribute grammar is well-defined if it is unique and unambiguous. This means that each attribute is defined only once and has a clear meaning and computation rule associated with it. It never generates a cyclic parse tree; such a grammar is called noncircular.
We call algorithm that transform a language into an equivalent representation in another language or formalism, such as through attribute evaluation a translation scheme.
Attribute Evaluators
Section titled “Attribute Evaluators”Attribute evaluators are responsible for computing the values of the attributes associated with the grammar symbols. The associated computation rule of an attribute grammar is called an action routine. It is included in the parser, which means the parser will execute the specific action routine during parsing when encountering the associated production rule.

Source: Book 2 page 176, 180
The left is a top-down attribute grammar to construct syntax tree. Now, it is modified so that each attribute on the grammar is associated with piece of code to compute that attribute (they are embedded within the attribute, delimited with curly braces).
The parser will generate syntax tree while parsing. For instance, when it encounters something like E → T TT, it should assign field ptr of T to st of TT (st and ptr are pointer fields). Moreover, the function make_leaf used in the rule F → const would probably be used to make a leaf node for constant term. They are sort of connecting pointer to create linked structure for the syntax tree.
Decorating Syntax Tree
Section titled “Decorating Syntax Tree”We modified the calculator language example to include types and declaration semantics. A sample program and its syntax tree as well as the production rule used to derive it can be seen below.

Source: Book 2 page 182, 183
The syntax tree follows a formalism called tree grammar. It is used to specify the structure and behavior of tree-like structures, such as parse trees or syntax tree. Unlike context-free grammars, which operate on linear sequences of symbols, tree grammars operate on hierarchical structures represented by trees.
Tree grammar is a form like A: B → C B. The A: B means that A is considered the part (or category) of B, and that B can be placed around C. For example, in read: item → id item, read is considered as an item and an item can be placed around id.
This tree grammar can also be included with attribute grammar like below.

Source: Book 2 page 185-187
Each attribute is associated with fragment of code to evaluate them. Some even contains control flow, checking symbol table (symtab), and error reporting. One thing to note is, it catches error by making a dummy type called error. This error type is associated with an error message in the symbol table.