CPL Fundamentals
Main Source:
- Book 1 chapter 1
- Book 2 chapter 1
- Programming language theory — Wikipedia
- Compiler — Wikipedia
Programming Languages
Section titled “Programming Languages”Programming language can be thought as a model of computation, they express computation with syntax (rules for constructing valid expression) and semantics (meaning of each expression). Programming language is typically defined with mathematical notation and formal methods, such as formal grammar.
Formal grammar is studied abstractly, the symbols used are often simplified to focus on the structure and rules of the grammar itself. For example, one production rules may look like . While this look meaningless, it can be modified such that it reflects a typical programming language construct.
One example: , , . This is an example of how variable assignment is defined as formal grammar. An assignment requires a single identifier (replaced from ), and expression . The expression can be expanded recursively if it includes another expression.
Programming Language Theory (PLT) is a branch of computer science that focuses on studying the design, implementation, characterization, and analysis of programming language. Some concerns of PLT:
- Syntax and Semantics: Syntax deals with the structure and grammar of programming languages, specifying how programs should be written. Semantics focuses on the meaning and interpretation of programs.
- Type Systems: Type systems help ensure program correctness and safety. They provide a way to classify and enforce constraints on the values that programs can manipulate. For example, when making variable assignments, we can enforce types (e.g., int, string), so that only variables with operations defined for those types can be operated on.
- Language Implementation: Programming language specify how computation is performed, language implementation techniques, including compilers, interpreters, runtime systems, and virtual machines are studied in order to carry out the actual computation.
Compilation & Interpretation
Section titled “Compilation & Interpretation”Essentially, programming languages are designed to help programmers develop their programs more easily. In the past, people had to code in machine language for their programs that targets specific machines. As machine language and hardware became more complex, an abstraction was created. People designed languages that helped them express machine language in a more human-readable way (initially similar to mathematical formula). These language expressions are then translated into actual machine language, this process is called compilation, and the program that does this is called a compiler.
A compiler translates high-level languages (source code) into target machine language that can be understood by the computer and executed by the user. Another way of running a program constructed in high-level languages is through an interpreter. Instead of translating the entire source code beforehand, an interpreter takes the source code (or typically in intermediate code) and input from the user, dynamically translating each instruction for the computer to execute.
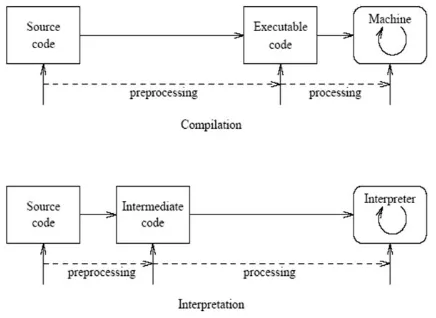
Source: https://www.researchgate.net/figure/nterpretation-vs-compilation_fig4_334289755
Some compilers do a preprocessing steps. The preprocessor operates on the source code at a textual level, manipulating or modifying it before the compilation steps. The C language preprocessing tasks includes expanding macros, including or importing other source files, excluding certain portions of code based on conditional macro, etc.
Compilation can be faster, since every decision is made beforehand. However, interpretation can be easier to debug, as instructions are executed on the fly. Although, it is possible to combine both approach through intermediate language.
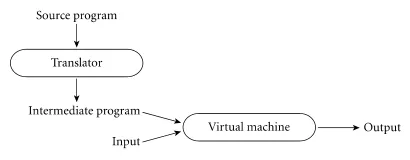
Source: Book 2 page 15
Interpretation is sometimes interchanged with compilation because they translate high-level code. Sometimes, some language is called interpreted if the initial translation process into intermediate code is simple enough.
Compilers
Section titled “Compilers”Compilers are program that translate computer code from one programming language (source language) to the target language, typically a lower-level language like assembly language, machine code, or bytecode.
Compiler Toolchain
Section titled “Compiler Toolchain”Toolchain is the collection of software tools that work together to transform source code into a working program. Compilation is just one of the process in a toolchain.
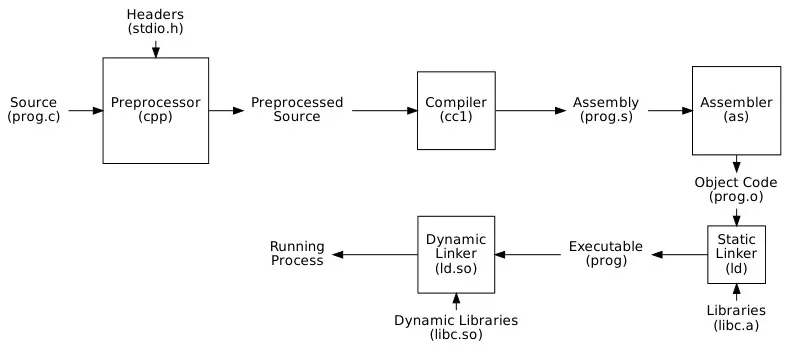
Source: Book 1 page 5
Let’s assume we are using language like C and C++.
-
Preprocessing: Preprocessor prepare the source code before the actual compilation. It handles directives like
#include,#define, and conditional compilation (#ifdef,#ifndef). For example, it may substitute a macro with actual value defined, including function defined in header files to the main source code, etc. -
Compilation: The main part of the toolchain, explained below.
-
Assembler: Compilation generates machine code, typically in the form of assembly language. This assembly language is lower-level enough to be considered as machine code, but it is still human-readable. Assembler takes generated assembly code to produce object files.
-
Linking: The object file contains real machine code to be executed on the CPU (typically represented in hexadecimal format), but it is not yet complete. The linking process is required to resolve external references used in our program to create a complete executable. For example, the function
printfis provided by the C standard library. Our source code, which is already in the form of machine code, should locate and load the definition of the function. The linker, divided into static and dynamic linker, loads and links together all object files and library files into memory.- Static Linker: Static linker links file by directly including pre-compiled libraries in our program final executable compile-time. Static libraries are identified by file with
.aformat on Unix or.libformat on Windows. - Dynamic Linker: Dynamic linker links pre-compiled libraries during runtime. Instead of including all the library code in the executable, the dynamic linker dynamically loads the required libraries into memory and resolves references to symbols during program execution. Dynamic libraries are identified by
.soformat on Unix or.dllformat on Windows.
- Static Linker: Static linker links file by directly including pre-compiled libraries in our program final executable compile-time. Static libraries are identified by file with
Compilation Process
Section titled “Compilation Process”The process of compilation can be broken down further into 6 (or 7) steps. The first 3 steps is the front end stage, where the compilers interact with high-level source code (language-dependent). The 3 (or 4) later steps are called back end stage, where the compiler focuses on generating code that is specific to the target machine from the output of front end (machine-dependent). The front end stages of compiler is same for any machine, but compiler may have different internal structure during the backend stages.
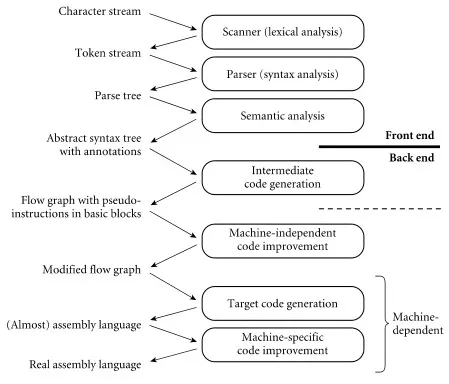
Source: Book 2 page 763
-
Lexical Analysis (Scanning): The first steps filter out unnecessary symbols from the source code, keeping only necessary input that comes from the language (we call it tokens). This includes removing white spaces and comments, while keeping identifier (e.g., variable names, function names), keywords, literals, operators, etc. The compiler may use the symbol table for storing global information about the compilation and code.
-
Syntax Analysis (Parsing): This steps analyze code correctness according to defined grammar. A parse tree (or sometimes abstract syntax tree (AST)) is constructed from the produced tokens from the previous step. The parse tree represents code organization based on grammar rules. For instance, a language may use context-free grammar do define its grammar. The compiler identifies if tokens belong to any valid categories. Compiler will continue constructing the tree whenever it encounters valid grammar, while encountering unexpected tokens gives a syntax error.
If a grammar is defined as
<while_statement> -> while <boolean_expression> <statement>, it basically means that a while statement must start with the keywordwhilefollowed by an expression that returns a boolean type, and finally a statement, which performs the actual operation. The boolean expression could be a comparison, equality checking, or other. If the compiler receiveswhile x = 3, this may not conform to the grammar sincex = 3is not a valid boolean expression. It is more like assignment, where the grammar may look like<identifier> = <literals>(i.e.,xis an identifier, a name given by the programmers, and 3 is a literal number).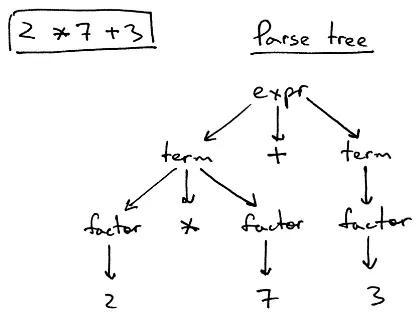
Source: https://ruslanspivak.com/lsbasi-part7/The above is an example of a parse tree. When the compiler sees
2 * 7 + 3, it recognizes that it is an expression. It knows that expression should be<term> +|-|*|/ <term>(i.e., a term combined with one choice of operator and followed by another term). It further recognizes that one of the term itself is nested with the operator*. A term can be obtained from a single factor, just like what 3 is, or consist of a factor multiplied by another term (which could be another single factor). -
Semantic Analysis: This step takes parse tree or AST from the previous step. The compiler checks the meaning of the code beyond its syntax. This can include type checking, scoping rules, and other language semantics. It may enforce that an integer type cannot be added to a string, or checking whether a variable is defined before it is used. This step produces a decorated AST which contain the semantic information.
For instance, language like Java won’t allow a string to be accessed with square bracket like an array (called string indexing). In contrast, Python allows you to get character at some index like
str[3]. This will be a compile-time error in Java, as it violates the language’s semantics and type system (certain rules may only be checked at runtime). -
Intermediate Code Generation (optional): Optionally, the AST may be translated into an intermediate language first. In some cases, the AST can be directly subjected to optimization techniques and transformed into target code without the need for an additional intermediate representation.
-
Machine-independent Optimization: These optimizations are applied without considering the specific target machine architecture. For example, some function can be inlined, meaning the actual content of a function is substituted to the call site. This can reduce the overhead of calling a function (i.e., reduce call stack and jumps operation).
-
Target Code Generation: Compiler translates the decorated AST into target code specific to the target machine architecture. The target code can be assembly language or directly machine code. The target code generation stage involves mapping the high-level constructs of the source language to the low-level instructions of the target machine.
-
Machine-dependent Optimization: Once the target code is generated, the compiler can apply additional optimizations that are specific to the target machine architecture. Examples of machine-dependent optimizations include instruction scheduling, register allocation, and target-specific code transformations.
Sometimes the process is divided into three-stage, it is called the three-stage compiler structure. In short, the 1st-3rd steps is the front end stage (language-dependent), the 4th step is middle end (machine-independent), and the 5th-6th step is the back end (machine-dependent).
Compilation Example
Section titled “Compilation Example”Suppose we have a hypothetical programming language, and we want to compile these three lines of code.
a = 5;b = 1;c = a + b;The scanning process removes unnecessary characters, such as whitespace, newline character, and semicolon that acts as end of line. For example, in the first line of code, we will obtain the tokens a, =, 5. The a doesn’t correspond to any keyword of the language, so it is considered as an identifier that comes from the user. The = is the assignment operator that indicates right-hand side value is assigned to left-hand side identifier. The 5 is a literal number, suppose it is an integer.
The language will need a grammar to describe what a valid expression is. The grammar for this language is specified with BNF. This will be explained more later at syntax.
<assignment>::= <identifier> = <expression><expression>::= <term> | <expression> + <term><term>::= <identifier> | <number><identifier>::= (list of valid character for identifier)<number>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9The ::= denotes “can be replaced by” or “is defined as” (i.e., the left-hand side can be replaced with expression on the right-hand side). The | denotes an “or”, it signifies that the left-hand side can be replaced to any one of the alternatives on the right-hand side.
In the <assignment>::= <identifier> = <expression> rule, it simply says that: for an assignment to be valid, it must consist of an identifier, followed by the = symbol right after it, and an expression. For the identifier itself to be valid, it must consist of valid character for identifier, denoted by the <identifier> rule. An expression must either be a term (which itself can be an identifier or a number) or can be another expression with the addition operator (+) and a term.
With the expression a = 5 or b = 1, the parser recognize that this conforms to the grammar rule for assignment (i.e., a is valid identifier and; 5 and 1 are expression which is replaced into a term and further replaced to number). The c = a + b is an assignment, in which the right-hand side expression follows the rule <expression>::= <expression> + <term>.
After all this parsing, the code appear to be correct, therefore an abstract syntax tree (AST) will be constructed. For the three lines of code, the constructed will look something like below.
= = / \ / \ / \ / \a 5 b 1
= / \ / \c + / \ a bThen, the tree is traversed and intermediate representation (IR) of this is created. The IR may look like this.
LOAD R1 5STORE a R1
LOAD R1 1STORE b R1
LOAD R1 aLOAD R2 bADD R1, R2 R3STORE c R3With this IR, we can finally transform the program into assembly code instructions, which a CPU can execute. For example, one may look like below.
mov eax, $5mov b, eax
mov eax, $1mov b, eax
mov eax, amov ebx, badd eax, ebxmov c, eaxTypes & Classification of Compilers
Section titled “Types & Classification of Compilers”Classification on how compiler process source code:
- One-pass Compiler: Scanning, parsing, semantic analysis, up to code generation is done in a single pass. Source code can be directly translated into final machine code without intermediate representation. Each step may be interleaved with another. Parse tree may not be generated, so semantic analysis is performed during parsing. It is said one-pass compiler to be smaller and faster, but difficult to make and may not be able to generate program as efficient as multi-pass compiler.
- Multi-pass Compiler: Processes the source several of times. This allows for better code generation at the higher cost of time and memory (depending on the number of passes and the algorithm itself).
Types of compilers:
- Cross Compiler: Compiler that generates executable code for a target platform different from the one on which the compiler itself runs. For example, compiling code on a Windows machine for execution on a Linux system.
- Decompiler: Takes an executable or binary file as input and attempts to reconstruct the original source code from which the executable was compiled. It is the reverse of compilation, going from low-level language to a higher-level language. Another term is disassembler, which is the reverse of assembler, converting machine code (e.g., in hex) back to its assembly language instruction.
- Transpiler: Also known as source-to-source compiler, it is a compiler that translate source language to an equivalent source code in the same or different language. This includes tools like obfuscator (transform source code into a less readable and more difficult-to-understand form), minimizer (reduces the size of the source code by removing unnecessary characters such as, whitespace, and comments), and optimizer (analyzes source code and optimize it).
- Just-In-Time (JIT) Compiler: A compiler that compiles code just-in-time it is executed. It dynamically compiles and optimizes code while the program is running.