Database Index
In database, index is a data structure that helps to improve performance in database queries, at the cost of extra space to store the data structure and additional maintenance. The idea of index is, rather than searching the whole table for particular value, we will instead create a special column that will narrow down the search space and help us locate the relevant data more quickly.
An index is a copy of a column, it is associated with a key and pointer. A key is a value that identify a data, it’s going to be a value that will be searched for. Each key will be associated with a pointer, which is the reference or address that points to the physical location of the corresponding data within the table.
Naive Example
Section titled “Naive Example”Let’s say we have a table of employee, it consists of name, ID, and department. For the example, we are going to find the department associated with a particular employee name.
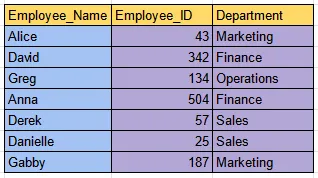
Data from: https://www.linkedin.com/pulse/database-index-selvamani-govindaraj
Suppose we are going to find the department for employee Derek. The naive approach is to check each row of Employee_Name column one by one from top to bottom. We will have to go through the table until we find someone with the name of Derek. In this case, we have to go through 4 row before we found Derek.
In a small table, the impact on query performance may not be significant. However, as the table size increases and the query becomes more frequent, it can have a noticeable effect on overall performance.
Now obviously we can improve the performance by sorting the table, so we can perform binary search. However, it will be harder in a scenario where we have to search based on multiple values, not just the name.
Binary search still requires accessing specific disk blocks/pages where the data resides. In a big sorted table, the data may not be stored contiguously, meaning that multiple disk blocks/pages may need to be read to complete the binary search. This can result in multiple I/O operations, especially if the desired data is distributed across different disk blocks.
Another downside of flat sorted table is the performance of insertion and deletion, as we need to maintain the sorted order of the table. If we insert a new record, we may need to shift all the subsequent records to make room for the new entry. This process can be time-consuming and resource-intensive.
B-Tree Index Example
Section titled “B-Tree Index Example”There are many ways to implement database indexes. One way is to maintain a column of key and pointer, arranged in a tree structure. The column will be sorted based on the key. This tree structure is called B-tree.
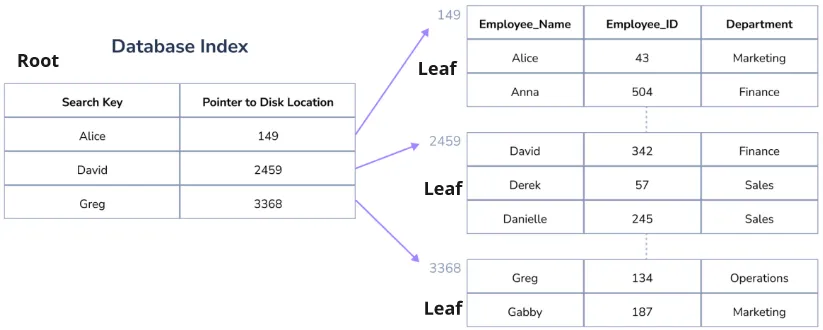
Source: https://www.linkedin.com/pulse/database-index-selvamani-govindaraj (with modification)
The tree will consist of many nodes, each node has different column of key and pointer. As said earlier, the key will be the terms that is being searched, such as name. Each column entry is associated with a pointer that refers to the child nodes, eventually referring to the leaf nodes.
Let’s say we are searching for name “Derek”.
- Start from the root node.
- Compare the search key with the keys stored in the root node.
- If the search key is found in the root node, the search is complete, and the corresponding data can be retrieved.
- Because Derek is higher than David but lower than Greg, we will follow the pointer associated with David.
- This comparison will keep being repeated until we find the data or arrived at the leaf nodes.
- We followed the pointer which led us to the disk location of 2459.
- Upon searching the node, we found Derek and its department.
In this case, we found Derek by doing 5 search, checking all the key on the root node and 2 key on the middle leaf nodes. So why is this index structure better than binary search?
One advantage is the balanced structure which results in reduced I/O operation. The binary search can only narrow down the search by half. In other word, it only divides the search space by 2. If we have 1 million data, we would need 20 comparison in average (). By 20 comparison, this mean we need to do the disk operation 20 times.
On the other hand, b-tree is more flexible in terms of the node maintained in each level. In contrast, a binary search can be represented in a tree like below.
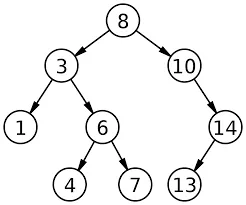
Source: https://en.wikipedia.org/wiki/Binary_search_tree
A b-tree node does not have to be 2, the number of node can be within a certain range. A node in a b-tree is sized to match the disk page size. Each node can contain many keys which all held in a single page. This is possible because an index entry consist only a key and a pointer, whereas binary search performed on sorted table requires all rows and column.
The compact representation of index entries in b-tree indexing enables a significant amount of data (the index keys) to fit within a single page. We can check a large amount of key in just a single I/O operations that retrieves the specific page.
Also, we don’t need to reorganize the node and all the disk pages every time insertion or deletion happens, this is because b-tree by itself is a self-balancing tree.
Index Architecture & Methods
Section titled “Index Architecture & Methods”Indexes can be organized differently:
- Clustered: A clustered index stores their index in the same order as how data rows are stored on disk. Clustered index can determine the physical order of the data rows in a table. Each table can have only one clustered index.
- Non-clustered: A non-clustered index contains copy of the indexed column(s) along with a pointer to the corresponding data row. Non-clustered index does not determine the physical order of the table rows. Instead, it provides a quick lookup mechanism to locate specific rows based on the indexed columns. There can be more than one non-clustered index on a table.
The b-tree example before is an example of non-clustered index.
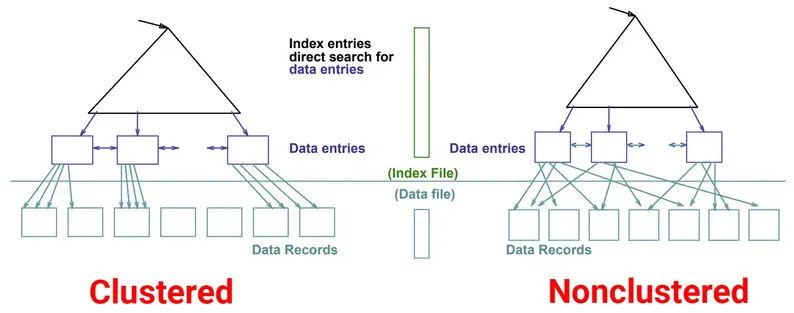
Source: https://josipmisko.com/posts/clustered-vs-non-clustered-index
Clustered index can significantly improve the performance of queries that involve range-based searches or sorting operations on the clustered index key. However, we need to maintain the sorted order of the data, possibly rearranging the data every insertion or deletion operation.
Non-clustered index can be efficient for query of data based on the indexed column(s) that involve filtering, sorting, or joining. However, it requires additional disk I/O operations to access the actual data rows after locating them through the index.
Types of Indexes
Section titled “Types of Indexes”- Bitmap Index: A bitmap index stores data in a bit array (bitmap) and answer query by performing bitwise operations. Each bit in the bitmap represents the yes or no of a particular value in the indexed column. Bitmap indexes are efficient for low cardinality columns (columns with a few distinct values) and can provide fast lookup and efficient boolean operations.
- Dense Index: Dense index contains an entry for every record in the indexed data structure. In other words, there is an index entry (containing key and pointer) for each data record in the table.
- Sparse Index: Sparse index contains an entry for some subset of record in the indexed data structure. It skips some records in the data structure, resulting in a smaller index size.
- Inverted Index: Inverted index maps a value to the records that contain them. Inverted indexes are commonly used in search engines which uses keyword as the value and the document or website as their records.
- Primary Index: Primary index is an index structure that is based on the primary key of a table. It determines the physical location of records in a data file. Data file is a specific file that is used to store the actual data records of a database, and may contain primary index data.
- Secondary Index: A secondary index is an index structure that is based on a non-primary key attribute of a table. Unlike the primary index, a secondary index does not determine the physical order of the records on disk. Instead, it provides an alternate way to access the data by creating an index on a specific attribute or combination of attributes. Secondary indexes are always dense, meaning they contain entries for all records in the data file. This is in contrast to primary indexes, which can be sparse, representing only a subset of the records.
- Hash Index: Hash index uses a hash function to map the indexed values to specific locations in the index structure. Hash indexes provide fast equality searches, but they are not well-suited for range queries or partial matches.
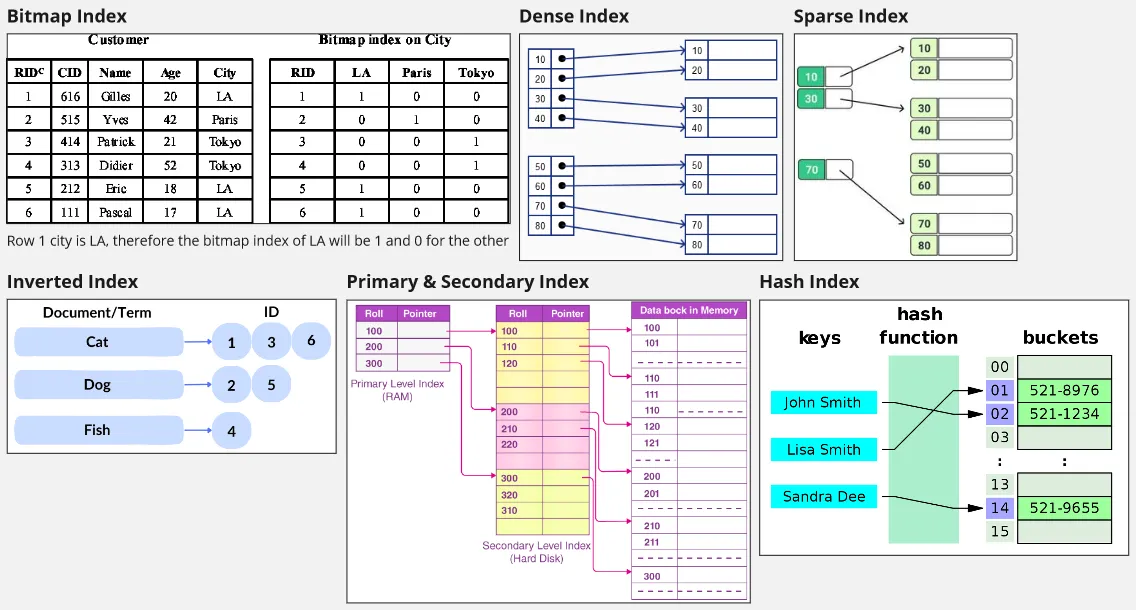
Source: Bitmap index, Dense index, Sparse index, Inverted index, Primary and secondary index, Hash index